

This blog post was published on Hortonworks.com before the merger with Cloudera. Some links, resources, or references may no longer be accurate.
Hortonworks announced the general availability of HDP 3.0 this year. You may read more about it here. Bundled with HDP 3.0, Apache Hive 3 with LLAP took a significant leap as a Enterprise Ready Real time Database Warehouse with transactional capabilities that continues to serve BI workloads with lower latencies. HDP 3.0 comes with exciting new capabilities – ACID support, materialized views, SQL constraints and Query result cache to name a few. Additionally, we continued to build and improve on the performance enhancements introduced in earlier releases.
In this blog, we will provide an update on our performance benchmark blog, comparing performance of HDP 3.0 to HDP 2.6.5. The noteworthy difference in benchmark is that all tables are by default transactional and written in ACID format, which means there are additional metadata (ROW_ID) columns to uniquely identify each row and support transactional semantics. Another key database capability used and tested here is SQL constraints. The hive-testbench schema has been enhanced to declare Primary-Foreign key, not null and unique constraints.
Hive 3 performs 2x faster in TPC-DS benchmark
The combined runtime for TPC-DS 99 queries on HDP 3.0 is 2x faster than HDP 2.6.5. This is really significant given all tables are ACID compliant. HDP 3.0 can run all original TPC-DS queries and no modifications are required.
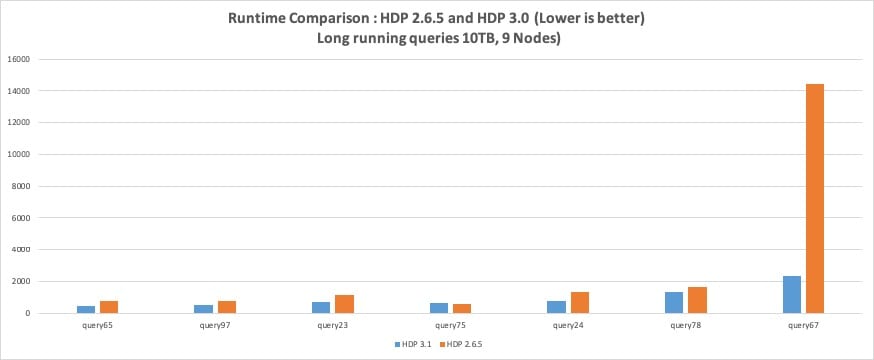
Following graph compares the runtime of 98 TPC-DS queries. Query 67, with runtime of ~15,000 on HDP 2.6.5 has not been shown to avoid skewing the graph.
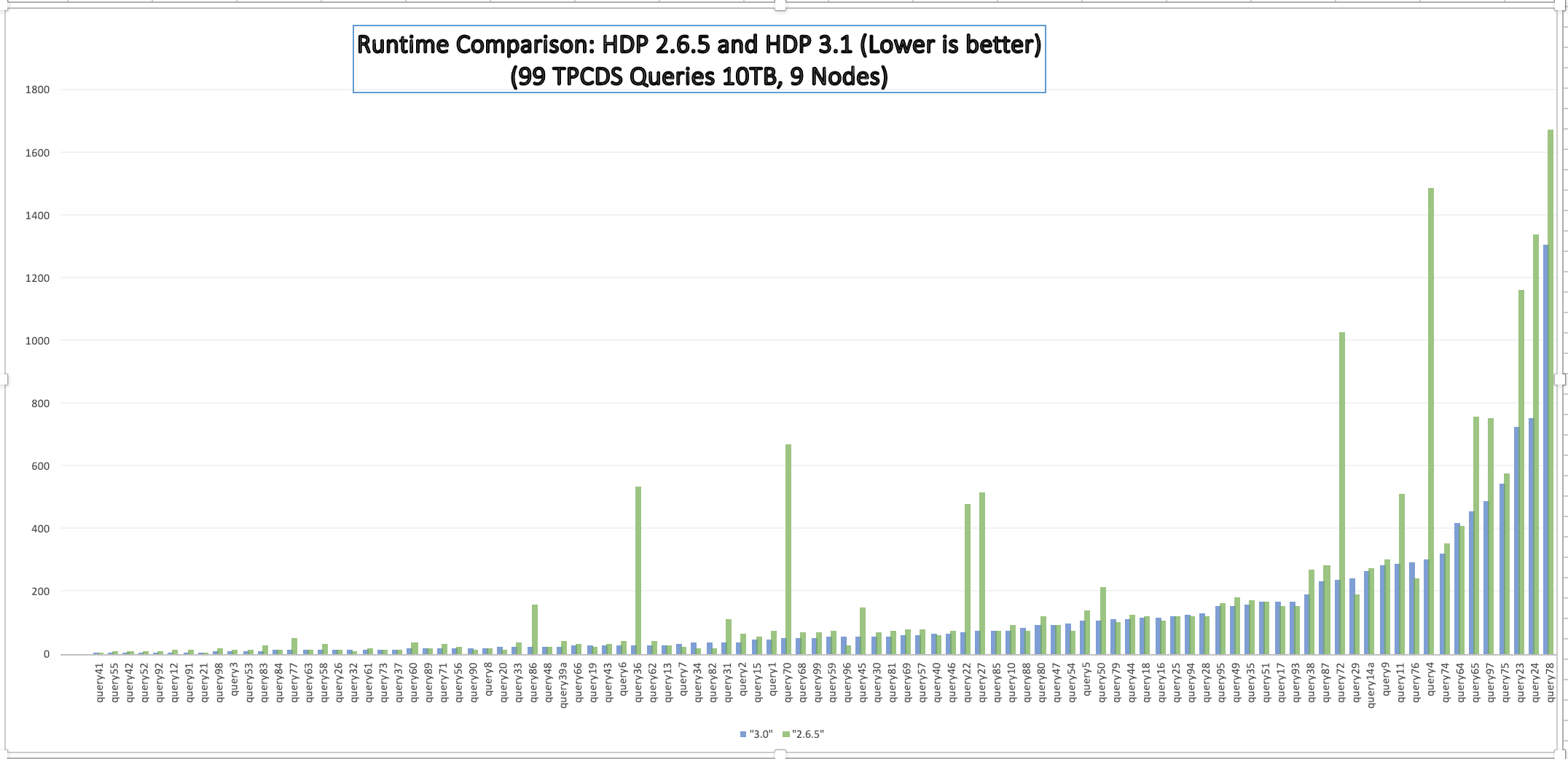
Magnifying on the right side of the graph for the longer running queries, you can see the most performance gains have come from this set.
Key observations:
- The total runtime on HDP 3.0 is approx 15,197 secs compared to 32,937 secs on HDP 2.6.5.
- About 70 queries run in less than 100 secs on this scale.
- HDP 3.0 is more than 5x faster than HDP 2.6.5 in about 5 queries.
Let’s dive into specific performance improvements.
Faster analytical queries with improved vectorization in 3.0
Vectorization has dramatic impact on query runtime as operations run in batches of 1024 rows versus a single row at a time. In HDP 3.0, OLAP operations such as window functions, rollup and grouping expressions run blazingly fast. For instance, query 67 – the longest running in HDP 2.6 that took ~15000 seconds runs in just about 2000 seconds. That is an impressive ~6x improvement. Other OLAP queries – query 27 and query 36 are showing more than 20x performance improvement.
Exploiting constraints for efficient query plans
SQL constraints impose certain restrictions on the data that can be inserted in the columns they are defined on. Hive’s Cost Based Optimizer can now use constraints to trigger specific query rewrites. These rewrites optimize query execution by removing redundant operations such as groupby on a unique key. Rewrites may also reduce the memory footprint by eliminating columns and/or joins. For instance, removing a Primary key – Foreign Key join based on constraint if the primary key table column appears solely in the join condition. Removing PK-FK join not only reduces the operator pipeline but also frees up memory required for primary key hashtables.
Constraint based optimizations not only reap benefit for the individual query but also improve overall system throughput with better memory utilization. TPC-DS query4, a long running query, improved ~4x times with constraint based optimization.
Dynamic Runtime Filtering on derived predicates
Dynamic Runtime Filtering reduces the number of rows coming out of one side of a join by applying a dynamic bloom filter built at runtime from the other side of the join. This dramatically improves performance of selective joins by removing rows from scan and further processing that will not qualify for the join.
Dynamic Runtime Filtering, introduced in HDP 2.6, built bloom filters on explicit query predicates only.
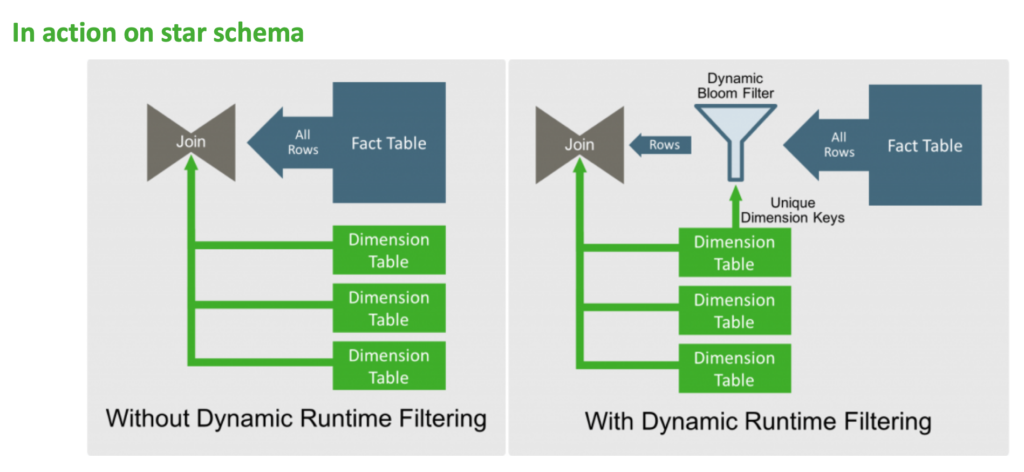
Starting in HDP 3.0, Dynamic Runtime Filtering now supports derived predicates. That means, explicit join predicate on source and destination table pair of the bloom filter is not required. Predicates transitively derived on equality join predicates are assessed based on their selectivity and the most effective bloom filters are inserted. In a star schema, bloom filters are not limited to dimension-fact table combos. Performance impact of this enhancement can be seen in TPC-DS query 1 which improved by 3x.
Besides these, in HDP 3.0 there are various improvements ranging from improvements in hashtable estimates to query rewrites and vectorization.
Materialized views
The benchmark results posted above are using the standard TPC-DS tables and no materialized views were created. However, since Materialized views can provide a significant performance boost, we decided to give it a spin over the benchmark and post initial testing results.
Materialized views, a key feature introduced in HDP 3.0, improves performance by executing and materializing a common table expression that can be further used to accelerate other similar queries. As new data is inserted into the base tables, although materialized views may get stale, CBO can continue to use them to accelerate queries. Materialized views are stored in a transactional format with partitioning and view maintenance is highly simplified in HDP 3.0 with various options on when to trigger the rebuild. Further, Hive’s CBO automatically detects which materialized views can be used and rewrites the query using it.
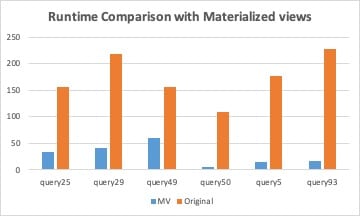
We built pre-joined materialized views on table pairs most commonly used together in TPC-DS queries, such as, store_sales-store_returns, catalog_sales-catalog_returns and web_sales-web_returns.
As depicted in the following graph, by using MV’s and avoiding the fact table joins altogether, queries run by an order of magnitude faster.
Hardware Configuration
9 worker nodes, each with:
- 256 GB RAM
- Intel(R) Xeon(R) CPU E5-2630 v3 @ 2.40GHz
- 2x HGST HUS726060AL4210 A7J0 disks for HDFS and YARN storage
- Cisco VIC 1227 10 Gigabit Network Connection
HDP 3.0 Software Configuration
- Ambari-managed HDP 3.1.0 stack
- Hive version = 3.1
- Tez version = 0.9.1
- LLAP container size: 180GB (per node)
- LLAP Heap Size: 128GB (per daemon)
- LLAP Cache Size: 32GB (per daemon)
- OS Setting: net.core.somaxconn set to 16k, ntpd and nscd running
- Data: ORCFile format, scale 10,000, with daily partitions on fact tables (load scripts available in the GitHub repository).
Editor's Choice

