

This blog post was published on Hortonworks.com before the merger with Cloudera. Some links, resources, or references may no longer be accurate.
 Source: Nvidia Blog Into the Woods: This Drone Goes Where No GPS Can
Source: Nvidia Blog Into the Woods: This Drone Goes Where No GPS Can
This is the 4th blog of the Hadoop Blog series (part 1, part 2, part 3, part 5). In this blog, we give examples of new use cases around Apache Hadoop 3.1 including GPU pooling/isolation to support deep learning use cases, lower total cost of ownership from erasure coding, and agility from containerization.
Use Cases
When we are in the outdoors, many of us often feel the need for a camera- that is intelligent enough to follow us, adjust to the terrain heights and visually navigate through the obstacles, while capturing panoramic videos. Here, I am talking about autonomous self-flying drones, very similar to cars on auto pilot. The difference is that we are starting to see proliferation of artificial intelligence into affordable, everyday use cases, compared to relatively expensive cars. These new use cases mean:
(1) They will need parallel compute processing to crunch through insane amount of data (visual or otherwise) in real time for inferences and training of deep learning neural network algorithms. This helps them distinguish between objects and get better with more data. Think like a leap of compute processing by 100x, due to the real time nature of the use cases
(2) They will need the deep learning software frameworks, so that data scientists & data engineers can deploy them as containerized microservices, closer to the data, quickly. Think like a leap from taking weeks to minutes to deploy
(3) They will generate tons of data to analyze. Think like a leap from petabyte scale to exabyte scale
A Giant Leap
Recently, Roni Fontaine at Hortonworks published a blog titled “How Apache Hadoop 3 Adds Value Over Apache Hadoop 2”, capturing the high-level themes. Now, we are glad to announce the official general availability of Apache Hadoop 3.1. This might seem like a small step, but this is a giant leap for the big data ecosystem. Apache Hadoop 3.1, building on Apache Hadoop 3.0, is the core enabling big data technology as we march into the fourth industrial revolution. This blog series picks up from the Data Lake 3.0 series last year and in this series, we will capture our technology deep-dive, performance results and joint blogs with our valued partners in the ecosystem.
High-level Architecture
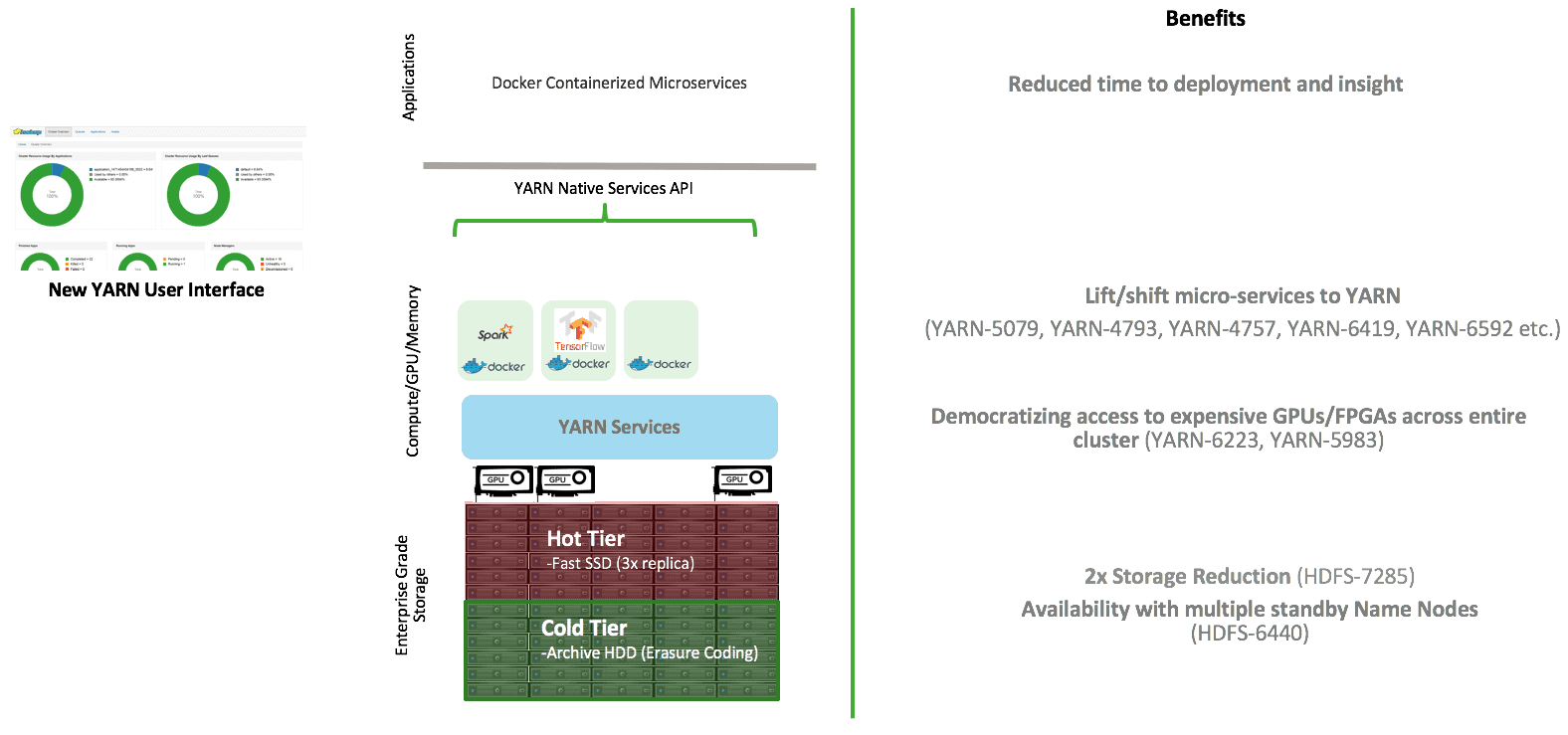
The diagram below captures the building blocks together at a high-level. If you have to tie this back to a fictitious self-flying drone company, the company will collect tons of raw images from the test drones’ built-in cameras for computer vision. Those images can be stored in the Apache Hadoop data lake in a cost-effective (with erasure coding), yet highly available manner (multiple standby namenodes). Instead of providing GPU machines to each of the data scientists, GPU cards are pooled across the cluster for access by multiple data scientists. GPU cards in each server can be isolated for sharing between multiple users. Support of docker containerized workloads means that data scientists/data engineers can bring the deep learning frameworks to the Apache Hadoop data lake and there is no need to have a separate compute/GPU cluster. GPU pooling allows the application of the deep learning neural network algorithms and the training of the data-intensive models using the data collected in the data lake at a speed almost 100x faster than regular CPUs. If the customer wants to pool the FPGA (field programmable gate array) resources instead of GPUs, this is also possible in Apache Hadoop 3.1. Additionally, use of affinity and anti-affinity labels allows us to control how we deploy the micro-services in the clusters- some of the components can be set to have anti-affinity so that they are always deployed in separate physical servers.
Now, the trained deep learning models can be deployed in the drones in the outdoors, which will then bring the data back to the data lake. Additionally, YARN native services API exposes the powerful YARN framework, programmatically and in a templatized manner. This is key to building an eco-system of microservices on Apache Hadoop data lake powered by YARN.
Key Takeaways
To summarize, Apache Hadoop 3.x architecture enables various use cases:
- Agility: Containerization support provides isolation and packaging of workloads and enables us to lift/shift existing as well new workloads such as deep learning frameworks (TensorFlow, Caffe etc). This enables data intensive microservices architecture through native YARN services API and brings the microservices closer to where data is. This also avoids creating yet another cluster for hosting the microservices away from the data.
- New Use Cases such as Graphical Processing Unit (GPU) pooling/isolation: GPUs are expensive resources and we want to enable our data scientists to share them quickly for proof of concepts. GPU pooling and isolation helps democratize the access across the company or department.
- Low Total Cost of Ownership: Erasure Coding helps reduce the storage overhead from 200% to 50%, as the volume of data grows.
Please stay tuned to this blog series and we will be bring a lot of exciting contents!
Learn More About Hadoop 3:
- First-Class Support for Long Running Services on Apache Hadoop YARN
- How Apache Hadoop 3 Adds Value Over Apache Hadoop 2
- Apache Hadoop 3.1.0 released. And a look back!
- Trying out Containerized Applications on Apache Hadoop YARN 3.1
Editor's Choice

