

This blog post was published on Hortonworks.com before the merger with Cloudera. Some links, resources, or references may no longer be accurate.
For this post, we take a technical deep-dive into one of the core areas of HBase. Specifically, we will look at how Apache HBase distributes load through regions, and manages region splitting. HBase stores rows of data in tables. Tables are split into chunks of rows called “regions”. Those regions are distributed across the cluster, hosted and made available to client processes by the RegionServer process. A region is a continuous range within the key space, meaning all rows in the table that sort between the region’s start key and end key are stored in the same region. Regions are non-overlapping, i.e. a single row key belongs to exactly one region at any point in time. A region is only served by a single region server at any point in time, which is how HBase guarantees strong consistency within a single row#. Together with the -ROOT- and .META. regions, a table’s regions effectively form a 3 level B-Tree for the purposes of locating a row within a table.
A Region in turn, consists of many “Stores”, which correspond to column families. A store contains one memstore and zero or more store files. The data for each column family is stored and accessed separately.
A table typically consists of many regions, which are in turn hosted by many region servers. Thus, regions are the physical mechanism used to distribute the write and query load across region servers. When a table is first created, HBase, by default, will allocate only one region for the table. This means that initially, all requests will go to a single region server, regardless of the number of region servers. This is the primary reason why initial phases of loading data into an empty table cannot utilize the whole capacity of the cluster.
Pre-splitting
The reason HBase creates only one region for the table is that it cannot possibly know how to create the split points within the row key space. Making such decisions is based highly on the distribution of the keys in your data. Rather than taking a guess and leaving you to deal with the consequences, HBase does provide you with tools to manage this from the client. With a process called pre-splitting, you can create a table with many regions by supplying the split points at the table creation time. Since pre-splitting will ensure that the initial load is more evenly distributed throughout the cluster, you should always consider using it if you know your key distribution beforehand. However, pre-splitting also has a risk of creating regions, that do not truly distribute the load evenly because of data skew, or in the presence of very hot or large rows. If the initial set of region split points is chosen poorly, you may end up with heterogeneous load distribution, which will in turn limit your clusters performance.
There is no short answer for the optimal number of regions for a given load, but you can start with a lower multiple of the number of region servers as number of splits, then let automated splitting take care of the rest.
One issue with pre-splitting is calculating the split points for the table. You can use the RegionSplitter utility. RegionSplitter creates the split points, by using a pluggable SplitAlgorithm. HexStringSplit and UniformSplit are two predefined algorithms. The former can be used if the row keys have a prefix for hexadecimal strings (like if you are using hashes as prefixes). The latter divides up the key space evenly assuming they are random byte arrays. You can also implement your custom SplitAlgorithm and use it from the RegionSplitter utility.
$ hbase org.apache.hadoop.hbase.util.RegionSplitter test_table HexStringSplit -c 10 -f f1
where -c 10, specifies the requested number of regions as 10, and -f specifies the column families you want in the table, separated by “:”. The tool will create a table named “test_table” with 10 regions:
13/01/18 18:49:32 DEBUG hbase.HRegionInfo: Current INFO from scan results = {NAME => 'test_table,,1358563771069.acc1ad1b7962564fc3a43e5907e8db33.', STARTKEY => '', ENDKEY => '19999999', ENCODED => acc1ad1b7962564fc3a43e5907e8db33,}
13/01/18 18:49:32 DEBUG hbase.HRegionInfo: Current INFO from scan results = {NAME => 'test_table,19999999,1358563771096.37ec12df6bd0078f5573565af415c91b.', STARTKEY => '19999999', ENDKEY => '33333332', ENCODED => 37ec12df6bd0078f5573565af415c91b,}
...
If you have split points at hand, you can also use the HBase shell, to create the table with the desired split points.
hbase(main):015:0> create 'test_table', 'f1', SPLITS=> ['a', 'b', 'c']
or
$ echo -e "anbnc" >/tmp/splits
hbase(main):015:0> create 'test_table', 'f1', SPLITSFILE=>'/tmp/splits'
For optimum load distribution, you should think about your data model, and key distribution for choosing the correct split algorithm or split points. Regardless of the method you chose to create the table with pre determined number of regions, you can now start loading the data into the table, and see that the load is distributed throughout your cluster. You can let automated splitting take over once data ingest starts, and continuously monitor the total number of regions for the table.
Auto splitting
Regardless of whether pre-splitting is used or not, once a region gets to a certain limit, it is automatically split into two regions. If you are using HBase 0.94 (which comes with HDP-1.2), you can configure when HBase decides to split a region, and how it calculates the split points via the pluggable RegionSplitPolicy API. There are a couple predefined region split policies: ConstantSizeRegionSplitPolicy, IncreasingToUpperBoundRegionSplitPolicy, and KeyPrefixRegionSplitPolicy.
The first one is the default and only split policy for HBase versions before 0.94. It splits the regions when the total data size for one of the stores (corresponding to a column-family) in the region gets bigger than configured “hbase.hregion.max.filesize”, which has a default value of 10GB. This split policy is ideal in cases, where you are have done pre-splitting, and are interested in getting lower number of regions per region server.
The default split policy for HBase 0.94 and trunk is IncreasingToUpperBoundRegionSplitPolicy, which does more aggressive splitting based on the number of regions hosted in the same region server. The split policy uses the max store file size based on Min (R^2 * “hbase.hregion.memstore.flush.size”, “hbase.hregion.max.filesize”), where R is the number of regions of the same table hosted on the same regionserver. So for example, with the default memstore flush size of 128MB and the default max store size of 10GB, the first region on the region server will be split just after the first flush at 128MB. As number of regions hosted in the region server increases, it will use increasing split sizes: 512MB, 1152MB, 2GB, 3.2GB, 4.6GB, 6.2GB, etc. After reaching 9 regions, the split size will go beyond the configured “hbase.hregion.max.filesize”, at which point, 10GB split size will be used from then on. For both of these algorithms, regardless of when splitting occurs, the split point used is the rowkey that corresponds to the mid point in the “block index” for the largest store file in the largest store.
KeyPrefixRegionSplitPolicy is a curious addition to the HBase arsenal. You can configure the length of the prefix for your row keys for grouping them, and this split policy ensures that the regions are not split in the middle of a group of rows having the same prefix. If you have set prefixes for your keys, then you can use this split policy to ensure that rows having the same rowkey prefix always end up in the same region. This grouping of records is sometimes referred to as “Entity Groups” or “Row Groups”. This is a key feature when considering use of the “local transactions” (alternative link) feature in your application design.
You can configure the default split policy to be used by setting the configuration “hbase.regionserver.region.split.policy”, or by configuring the table descriptor. For you brave souls, you can also implement your own custom split policy, and plug that in at table creation time, or by modifying an existing table:
HTableDescriptor tableDesc = new HTableDescriptor("example-table");
tableDesc.setValue(HTableDescriptor.SPLIT_POLICY, AwesomeSplitPolicy.class.getName());
//add columns etc
admin.createTable(tableDesc);
If you are doing pre-splitting, and want to manually manage region splits, you can also disable region splits, by setting “hbase.hregion.max.filesize” to a high number and setting the split policy to ConstantSizeRegionSplitPolicy. However, you should use a safeguard value of like 100GB, so that regions does not grow beyond a region server’s capabilities. You can consider disabling automated splitting and rely on the initial set of regions from pre-splitting for example, if you are using uniform hashes for your key prefixes, and you can ensure that the read/write load to each region as well as its size is uniform across the regions in the table.
Forced Splits
HBase also enables clients to force split an online table from the client side. For example, the HBase shell can be used to split all regions of the table, or split a region, optionally by supplying a split point.
hbase(main):024:0> split 'b07d0034cbe72cb040ae9cf66300a10c', 'b'
0 row(s) in 0.1620 seconds
With careful monitoring of your HBase load distribution, if you see that some regions are getting uneven loads, you may consider manually splitting those regions to even-out the load and improve throughput. Another reason why you might want to do manual splits is when you see that the initial splits for the region turns out to be suboptimal, and you have disabled automated splits. That might happen for example, if the data distribution changes over time.
How Region Splits are implemented
As write requests are handled by the region server, they accumulate in an in-memory storage system called the “memstore”. Once the memstore fills, its content are written to disk as additional store files. This event is called a “memstore flush”. As store files accumulate, the RegionServer will “compact” them into combined, larger files. After each flush or compaction finishes, a region split request is enqueued if the RegionSplitPolicy decides that the region should be split into two. Since all data files in HBase are immutable, when a split happens, the newly created daughter regions will not rewrite all the data into new files. Instead, they will create small sym-link like files, named Reference files, which point to either top or bottom part of the parent store file according to the split point. The reference file will be used just like a regular data file, but only half of the records. The region can only be split if there are no more references to the immutable data files of the parent region. Those reference files are cleaned gradually by compactions, so that the region will stop referring to its parents files, and can be split further.
Although splitting the region is a local decision made at the RegionServer, the split process itself must coordinate with many actors. The RegionServer notifies the Master before and after the split, updates the .META. table so that clients can discover the new daughter regions, and rearranges the directory structure and data files in HDFS. Split is a multi task process. To enable rollback in case of an error, the RegionServer keeps an in-memory journal about the execution state. The steps taken by the RegionServer to execute the split are illustrated by Figure 1. Each step is labeled with its step number. Actions from RegionServers or Master are shown in red, while actions from the clients are show in green.
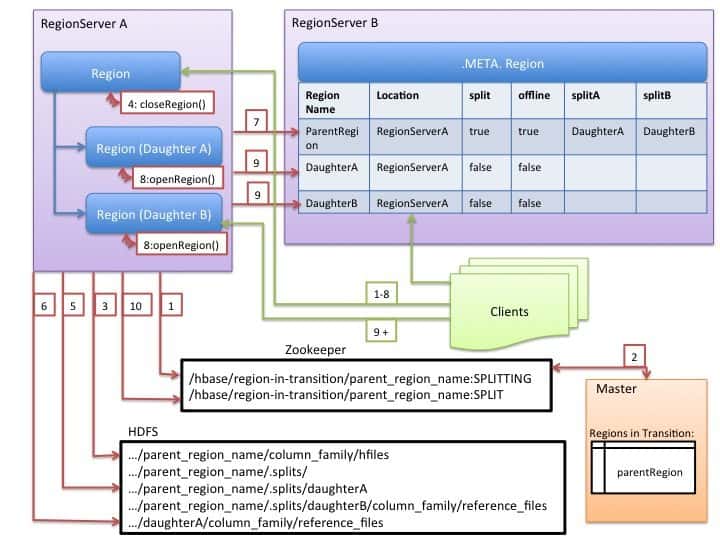
1. RegionServer decides locally to split the region, and prepares the split. As a first step, it creates a znode in zookeeper under /hbase/region-in-transition/region-name in SPLITTING state.
2. The Master learns about this znode, since it has a watcher for the parent region-in-transition znode.
3. RegionServer creates a sub-directory named “.splits” under the parent’s region directory in HDFS.
4. RegionServer closes the parent region, forces a flush of the cache and marks the region as offline in its local data structures. At this point, client requests coming to the parent region will throw NotServingRegionException. The client will retry with some backoff.
5. RegionServer create the region directories under .splits directory, for daughter regions A and B, and creates necessary data structures. Then it splits the store files, in the sense that it creates two Reference files per store file in the parent region. Those reference files will point to the parent regions files.
6. RegionServer creates the actual region directory in HDFS, and moves the reference files for each daughter.
7. RegionServer sends a Put request to the .META. table, and sets the parent as offline in the .META. table and adds information about daughter regions. At this point, there won’t be individual entries in .META. for the daughters. Clients will see the parent region is split if they scan .META., but won’t know about the daughters until they appear in .META.. Also, if this Put to .META. succeeds, the parent will be effectively split. If the RegionServer fails before this RPC succeeds, Master and the next region server opening the region will clean dirty state about the region split. After the .META. update, though, the region split will be rolled-forward by Master.
8. RegionServer opens daughters in parallel to accept writes.
9. RegionServer adds the daughters A and B to .META. together with information that it hosts the regions. After this point, clients can discover the new regions, and issue requests to the new region. Clients cache the .META. entries locally, but when they make requests to the region server or .META., their caches will be invalidated, and they will learn about the new regions from .META..
10. RegionServer updates znode /hbase/region-in-transition/region-name in zookeeper to state SPLIT, so that the master can learn about it. The balancer can freely re-assign the daughter regions to other region servers if it chooses so.
11. After the split, meta and HDFS will still contain references to the parent region. Those references will be removed when compactions in daughter regions rewrite the data files. Garbage collection tasks in the master periodically checks whether the daughter regions still refer to parents files. If not, the parent region will be removed.
Region Merges
Unlike region splitting, HBase at this point does not provide usable tools for merging regions. Although there are HMerge, and Merge tools, they are not very suited for general usage. There currently is no support for online tables, and auto-merging functionality. However, with issues like OnlineMerge, Master initiated automatic region merges, ZK-based Read/Write locks for table operations, we are working to stabilize region splits and enable better support for region merges. Stay tuned!
Conclusion
As you can see, under-the-hood HBase does a lot of housekeeping to manage regions splits and do automated sharding through regions. However, HBase also provides the necessary tools around region management, so that you can manage the splitting process. You can also control precisely when and how region splits are happening via a RegionSplitPolicy.
The number of regions in a table, and how those regions are split are crucial factors in understanding, and tuning your HBase cluster load. If you can estimate your key distribution, you should create the table with pre-splitting to get the optimum initial load performance. You can start with a lower multiple of number of region servers as a starting point for initial number of regions, and let automated splitting take over. If you cannot correctly estimate the initial split points, it is better to just create the table with one region, and start some initial load with automated splitting, and use IncreasingToUpperBoundRegionSplitPolicy. However, keep in mind that, the total number of regions will stabilize over time, and the current set of region split points will be determined from the data that the table has received so far. You may want to monitor the load distribution across the regions at all times, and if the load distribution changes over time, use manual splitting, or set more aggressive region split sizes. Lastly, you can try out the upcoming online merge feature and contribute your use case.
Editor's Choice


Nice explanation. I had a doubt, if we have 5 region servers, how many total number of directories will HBase have?
Hi, As you mentioned you are working for goo solution for HBase regions merging, do you have a good solution?
This article seems outdated in terms of what tools are really available.
When the article was written 8 years ago the stable version of HBase was 0.94.x
Whereas the current stable version is 2.4.4. https://hbase.apache.org/downloads.html