

The 100% open source and community driven innovation of Apache Hive 2.0 and LLAP (Long Last and Process) truly brings agile analytics to the next level. It enables customers to perform sub-second interactive queries without the need for additional SQL-based analytical tools, enabling rapid analytical iterations and providing significant time-to-value.
TRY HIVE LLAP TODAY
- Read about how Hive with LLAP can bring sub-second query to your big data lake, please go here: https://hortonworks.com/apache/hive/
2. If you’re looking for a quick test on a single node, the Hortonworks Sandbox 2.5. Download the Sandbox and this LLAP tutorial will have you up and running in minutes. Note: you’ll need a system with at least 16 GB of RAM for this approach.
Last week we discussed Apache Hive’s shift to a memory-centric architecture and showed how this new architecture delivers dramatic performance improvements, especially for interactive SQL workloads. Today we’ll compare these results with Apache Impala (Incubating), another SQL on Hadoop engine, using the same hardware and data scale.
Comparing Apache Hive LLAP to Apache Impala (Incubating)
Before we get to the numbers, an overview of the test environment, query set and data is in order. The Impala and Hive numbers were produced on the same 10 node d2.8xlarge EC2 VMs. To prepare the Impala environment the nodes were re-imaged and re-installed with Cloudera’s CDH version 5.8 using Cloudera Manager. The defaults from Cloudera Manager were used to setup / configure Impala 2.6.0. It is worth pointing out that Impala’s Runtime Filtering feature was enabled for all queries in this test.
Data: While Hive works best with ORCFile, Impala works best with Parquet, so Impala testing was done with all data in Parquet format, compressed with Snappy compression. Data was partitioned the same way for both systems, along the date_sk columns. This was done to benefit from Impala’s Runtime Filtering and from Hive’s Dynamic Partition Pruning.
Queries: After this setup and data load, we attempted to run the same set query set used in our previous blog (the full queries are linked in the Queries section below.) Impala was designed to be highly compatible with Hive, but since perfect SQL parity is never possible, 5 queries did not run in Impala due to syntax errors. For example, one query failed to compile due to missing rollup support within Impala. It may have been possible to find Impala-specific workarounds to these gaps, but no attempt was made to do so since these results could not be directly compared. Here we will only draw comparison between the queries that ran on both engines with identical syntax.
Timings: For both systems, all timings were measured from query submission to receipt of the last row on the client side.
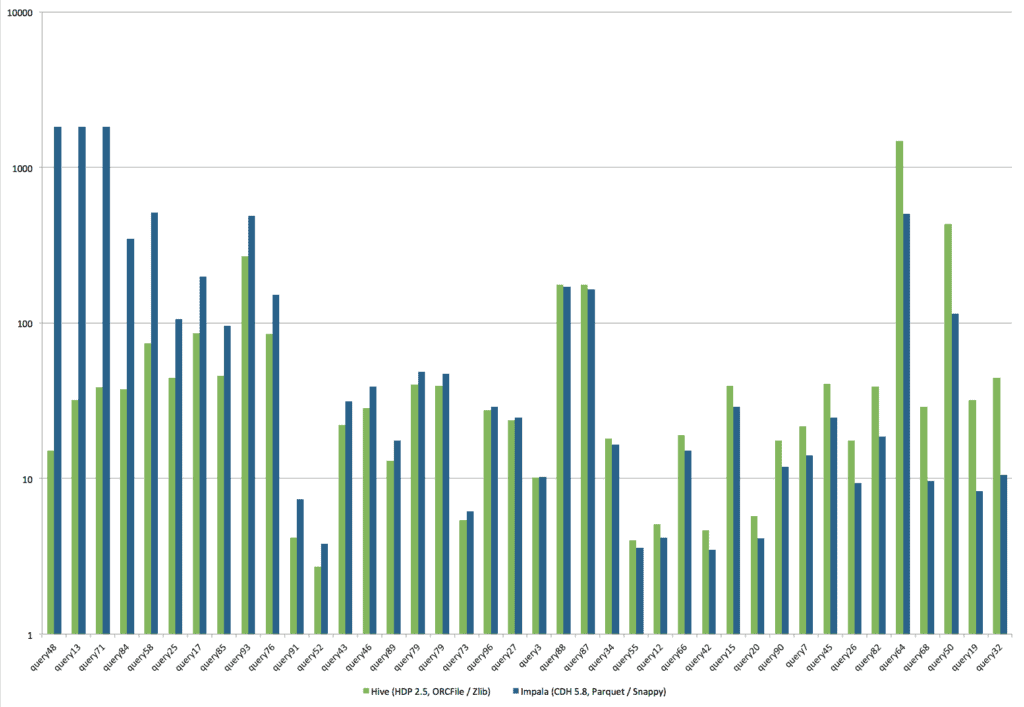
This bar chart shows the runtime comparison between the two engines:
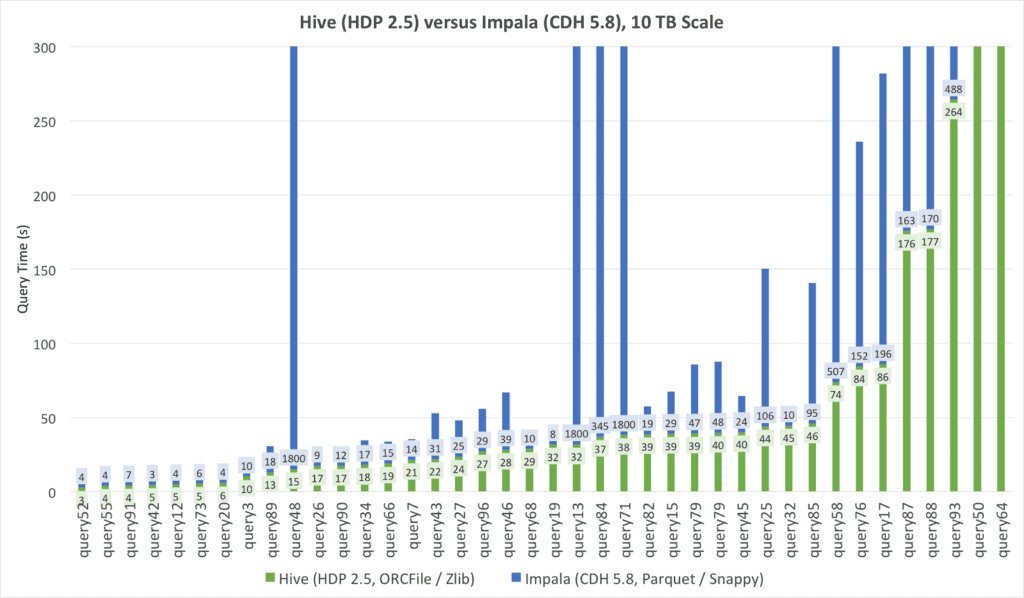
One thing that quickly stands out is that some Impala queries ran to timeout (30 minutes), including 4 queries that required less than 1 minute with Hive. This makes a direct comparison a bit challenging.
A more helpful way of comparing the engines is to examine how many of the queries complete within given time bands. The chart below shows the cumulative number of queries that complete within the given time. The x axis in this chart moves in discrete 30 second intervals.
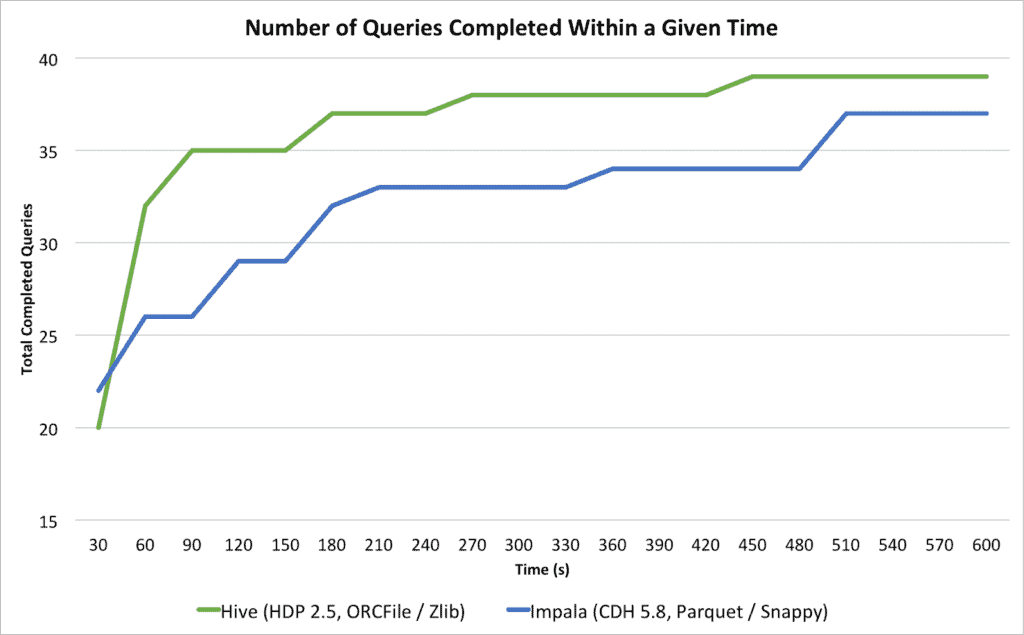
The first thing we see is that Impala has an advantage on queries that run in less than 30 seconds. 22 queries completed in Impala within 30 seconds compared to 20 for Hive. The positions change as query times get a bit longer: By the time we reach one minute, Hive has completed 32 queries compared to Impala’s 26 and the relative position does not switch again. This shows that Impala performs well with less complex queries but struggles as query complexity increases. On the other hand Hive, with the introduction of LLAP, gets good performance at the low end while retaining Hive’s ability to perform well at mid to high query complexity.
Since some of the runtimes can be hard to see, a full table of runtimes is included toward the end.
Conclusion
As more Hadoop workloads move to interactive and user-facing, teams face the unpleasant prospect of using one SQL engine just for interactive while they use Hive for everything else. This introduces a lot of cost and complexity to Hadoop because it really means separate specialized teams to tune, troubleshoot and operate two very different SQL systems.
Hive LLAP fundamentally changes this landscape by bringing Hive’s interactive performance in line with SQL engines that are custom-built to only solve interactive SQL. With Hive LLAP you can solve SQL at Speed and at Scale from the same engine, greatly simplifying your Hadoop analytics architecture.
Test Environments
Software and Data:
| Hive (HDP 2.5) | Impala (CDH 5.8) |
| Hive 2.1.0
Tez 0.8.4 Hadoop 2.7.3 ORCFile format with zlib compression All queries run through LLAP |
Impala 2.6
Hadoop 2.6.0 Runtime Filtering Optimization Enabled Parquet format with snappy compression |
Other Settings:
- All HDP software was deployed using Apache Ambari using HDP 2.5 software. All defaults were used in our installation.
- All CDH software was deployed using Cloudera Manager.
Hardware:
- 10x d2.8xlarge EC2 nodes were used for both Hive and Impala testing. Separate, fresh installs were used and data was generated in the native environment.
OS Configuration:
For the most part, OS defaults were used with 1 exception:
- /proc/sys/net/core/somaxconn = 4000
Data:
- TPC-DS Scale 10000 data (10 TB), partitioned by date_sk columns
- Hive data was stored in ORC format with Zlib compression.
- Impala data was stored in Parquet format with snappy compression.
Queries:
- Queries were taken from the Hive Testbench https://github.com/hortonworks/hive-testbench/tree/hive14 The same query text was used both for Hive and Impala. Only queries that worked in both environments were included.
Reference: Full Table of Hive and Impala runtimes.
| Query Number | Apache Hive
(HDP 2.5, ORCFile / Zlib, 10 TB) |
Apache Impala (Incubating)
(CDH 5.8, Parquet/Snappy, 10 TB) |
| query52 | 2.68 | 3.82 |
| query55 | 3.97 | 3.56 |
| query91 | 4.11 | 7.3 |
| query42 | 4.59 | 3.46 |
| query12 | 5.04 | 4.11 |
| query73 | 5.37 | 6.18 |
| query20 | 5.71 | 4.09 |
| query3 | 10.01 | 10.16 |
| query89 | 13.02 | 17.59 |
| query48 | 15.18 | 1800 |
| query26 | 17.36 | 9.3 |
| query90 | 17.39 | 11.79 |
| query34 | 18.04 | 16.52 |
| query66 | 18.89 | 14.94 |
| query7 | 21.34 | 13.91 |
| query43 | 21.97 | 31.02 |
| query27 | 23.56 | 24.51 |
| query96 | 27.12 | 28.59 |
| query46 | 28.21 | 38.69 |
| query68 | 28.69 | 9.65 |
| query19 | 31.75 | 8.32 |
| query13 | 31.8 | 1800 |
| query84 | 36.96 | 345.31 |
| query71 | 38.24 | 1800 |
| query82 | 38.71 | 18.65 |
| query15 | 38.99 | 28.52 |
| query79 | 39.11 | 46.72 |
| query79 | 39.62 | 48 |
| query45 | 40.12 | 24.32 |
| query25 | 43.92 | 106.28 |
| query32 | 44.52 | 10.43 |
| query85 | 45.94 | 94.65 |
| query58 | 73.81 | 506.89 |
| query76 | 84.42 | 151.55 |
| query17 | 85.785 | 196.07 |
| query87 | 175.76 | 163.34 |
| query88 | 177.05 | 169.5 |
| query93 | 264.34 | 487.69 |
| query50 | 434.38 | 113.93 |
| query64 | 1475.59 | 497.14 |
Try Hive LLAP Today
Trying Hive LLAP is simple in the cloud or on your laptop.
- Want a quick start in the cloud? Hortonworks Data Cloud (in Technical Preview) has you covered and this handy tutorial will guide you each step of the way.
- If you’re looking for a quick test on a single node, the Hortonworks Sandbox 2.5. Download the Sandbox and this LLAP tutorial will have you up and running in minutes. Note: you’ll need a system with at least 16 GB of RAM for this approach.
- Hive LLAP is also included in all on-prem installs of HDP 2.5, requiring just a few clicks to enable.
It’s easy to take a test drive, so we encourage you to start today and share your experiences with us on the Hortonworks Community Connection.
Editor's Choice


Good comparison. Thanks 🙂