

This blog post was published on Hortonworks.com before the merger with Cloudera. Some links, resources, or references may no longer be accurate.
Earlier we talked about reasons for integrating Druid and Hive in a THREE-PART SERIES (Part 1, Part 2 , Part 3) OF DOING ULTRA FAST OLAP ANALYTICS WITH APACHE HIVE AND DRUID. Since then we have spent even more of our time and efforts on — bug fixes, correctness, performance and supporting new features.
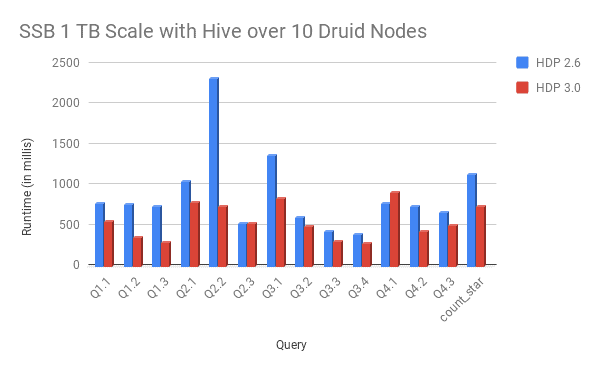
Today, We are excited to share an update on our performance benchmark blog and compare the performance numbers of running 1 TB OLAP benchmark at 1 TB Scale for HDP 2.6 vs HDP 3.0. The benchmark results show an overall improvement of 42% in average query performance.
There are numerous improvements that went into HDP 3.0 and the performance improvements shown are an aggregate result of all of them. Here are some of the more noteworthy improvements related to Druid-Hive integration :
-
- Druid Expressions Support – HIVE-18893/ CALCITE-2170 added support for Druid expressions in Hive. In HDP 3.0, Hive can push the computation of SQL expressions as part of a Druid query and they can be evaluated by Druid.
- Use of Scan Query instead of Select Query – In HDP 3.0 we use Druid Scan query instead of Select Query. Scan Query is a streaming version of Select Query which returns the results in a compact streaming format. Scan query also does not need all the results to be retained in memory before they can be returned to Hive. This improves the memory usage of the historical nodes too.
- GroupBy Query Improvements – Many optimizations are done in order to address the performance of GroupBy queries on Druid side. Main ones are –
- Better column pruning – In some cases when hive cannot push any operator to druid, hive ended up pulling all the columns from druid. This led to lots of unnecessary data transfer between druid and hive. HIVE-15619 improved the column pruner logic to only fetch the columns from druid which are required to answer a query.
- Druid Version upgrade from 0.10.0 to 0.12.2 – HDP 3.0 comes with latest version of Druid i.e 0.12.2 which has many new features, performance enhancements and bug-fixes over the previous version.
More details about the benchmark –
To benchmark Hive/Druid integration we used the Star-Schema Benchmark which is based on TPC-H benchmark. Overall the SSB benchmark is meant to simulate the process of iteratively and interactively querying a data warehouse to play what-if scenarios, drill down and better understand trends, as opposed to the pre-canned, batch-style reports used by TPC-H.
QUERY ADJUSTMENTS
In our previous post, we made some cosmetic query adjustments like removing the Order By clause and rewriting the between predicate into two separate inequality predicates.
It is worth noting that in this blog-post we are running the original SSB queries as it is without any modifications. The Hive Query optimizer is now able to generate optimized plans without any Query adjustments on the user side.
PERFORMANCE RESULTS AT 1TB SCALE
In the benchmark SSB queries were run via JDBC through HiveServer2 and backed by Druid. Table below shows the improvements in min,max and average query response times.
| HDP Version | Average Query time | Min Query Time | Max Query Time |
| HDP 2.6 | 960 | 481 | 2700 |
| HDP 3.0 | 556 | 288 | 908 |
| % Improvement | 42.1 | 40.1 | 66.4 |
For additional reference here are the specifics of the cluster where these numbers were generated:
- 10 nodes
- 2x Intel(R) Xeon(R) CPU E5-2640 v2 @ 2.00GHz with 16 CPU threads each
- 256 GB RAM per node
- 6x WDC WD4000FYYZ-0 1K02 4TB SCSI disks per node
The GitHub repo also contains some additional tuning notes with detailed Java command line arguments.
Finally If you are using Druid with HDP 2.6, We encourage you to upgrade to try Druid in HDP 3.0 and give us your feedback in the Hortonworks Community.
Editor's Choice


Can you please share the metrics of the SSB benchmark test with druid with concurrent user details ?