

Hive / Druid integration means Druid is BI-ready from your tool of choice
This is Part 3 of a Three-Part series (Part 1, Part 2) of doing ultra fast OLAP Analytics with Apache Hive and Druid.
Connect Tableau to Druid
Previously we talked about how the Hive/Druid integration delivers screaming-fast analytics, but there is another, even more powerful benefit to the integration. Any Druid table built using the integration is just another table in Hive, meaning you can query it using ordinary SQL from any BI tool. In this blog we’ll show how easy it is to hook Tableau up to Druid, but this works for any BI tool, Qlik, Spotfire, Microstrategy, Excel, you name it. Connecting from any of these tools is possible using an ordinary Hive connection and takes advantage of the high-quality ODBC and JDBC drivers Hortonworks already provides.
Let’s dive into connecting Tableau to Druid to see how it works. We start off with an ordinary connection dialog, connecting to Hive as you normally would, using the Hortonworks Hadoop Hive connection type in Tableau.
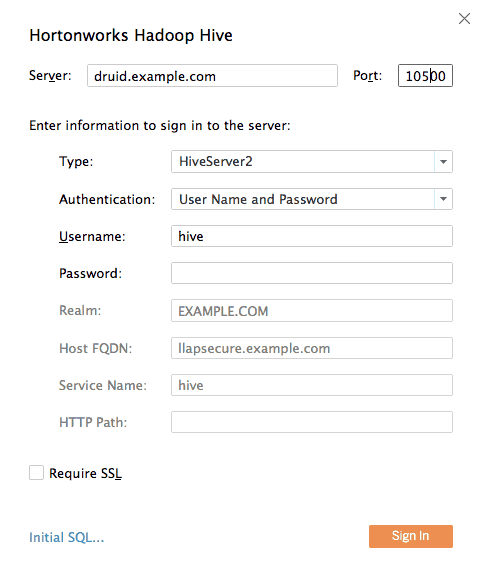
Hortonworks Hadoop Hive
Notice that we’re connecting to port 10500 rather than the usual port 10000 because we’re connecting to Hive LLAP.
Next, the Druid cube is visible as an ordinary Hive table and can be loaded into Tableau just like any other table. We’re continuing with the SSB data so we’ll load the SSB druid cube as a data source. As far as Tableau cares this is just a regular Hive table.
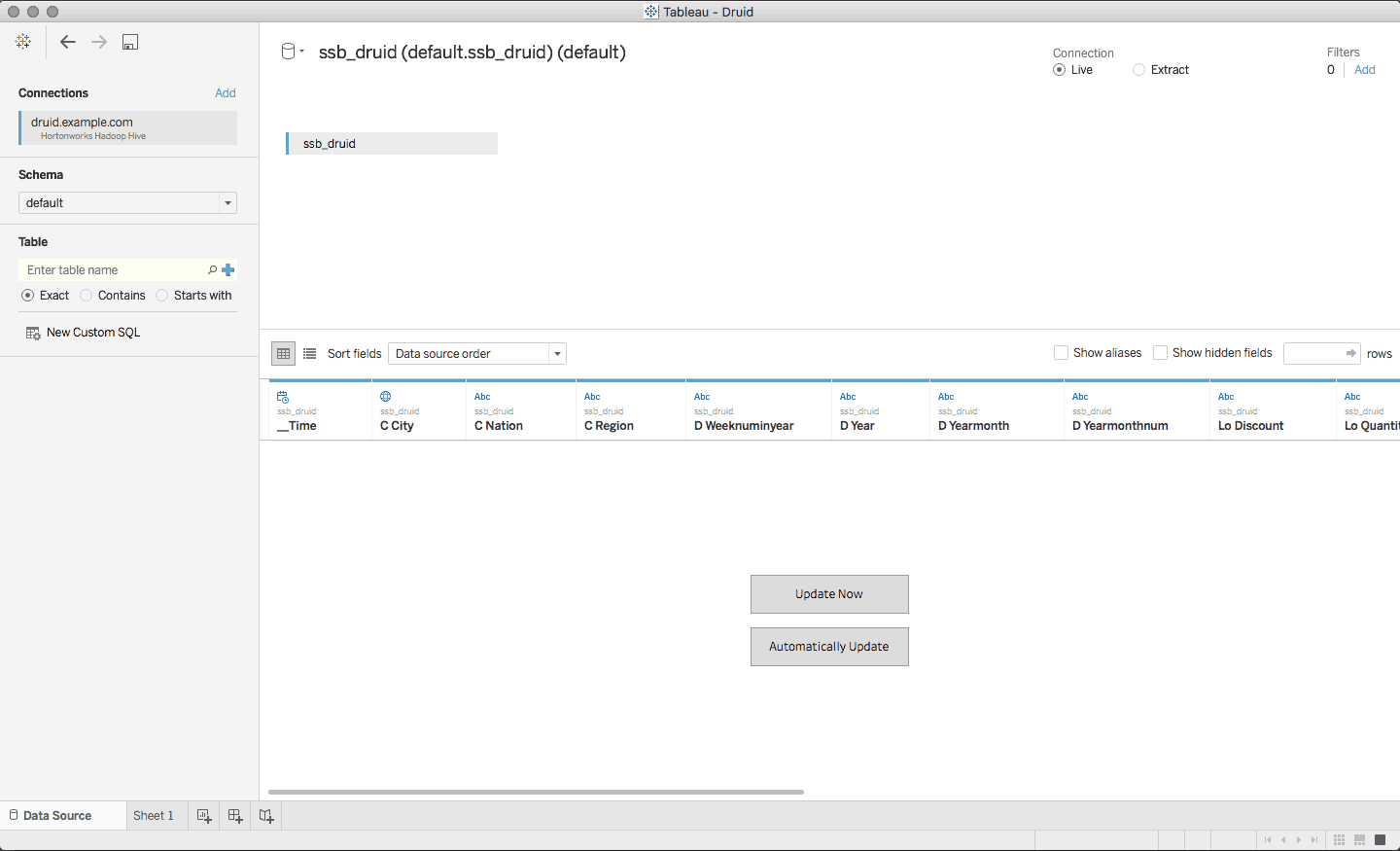
Druid Table
The result is that queries fired by Tableau can be pushed down into Druid, and end users see extremely fast access to their data.
This animation shows a real-time view of accessing Druid in Tableau, using Hive LLAP.
As you can see the response time is easily within interactive time scales.
Try It Today
Druid is available as a Technical Preview in HDP 2.6. In addition to the Hive/Druid integration, Hortonworks has made it easy to deploy, configure and monitor Druid using Apache Ambari, making it easy to get started. With these simplifications, a knowledgeable Hadoop user should be able to reproduce anything in this document within a few hours with the help of the materials on GitHub. We encourage you to try Druid, in HDP or on Hortonworks Data Cloud and give us your feedback in the Hortonworks Community.
Editor's Choice

