


This blog post was published on Hortonworks.com before the merger with Cloudera. Some links, resources, or references may no longer be accurate.
This is the 6th blog of the Hadoop Blog series (part 1, part 2, part 3, part 4, part 5). In this blog, we will explore how to leverage Docker for Apache Spark on YARN for faster time to insights for data intensive workloads at unprecedented scale.
Apache Spark applications usually have a complex set of required software dependencies. Especially with Pyspark/R etc., Spark applications may require specific versions of these dependencies to be installed on all the cluster hosts where Spark executors run, sometimes with conflicting versions. Installing such dependencies on the cluster machines poses package isolation challenges as well as organizational challenges – typically the cluster machines are maintained by specialized operations teams. Existing solutions involving things like virtualenv or conda are involved and / or inefficient (because of per-app dependency downloads).
Docker support in Apache Hadoop 3 can be leveraged by Apache Spark for addressing these long standing challenges related to package isolation – by converting application’s dependencies to be containerized via docker images. With this solution, users can bring their own versions of python, libraries, without heavy involvement of admins and have an efficient solution with docker image layer caching.
Leveraging Docker for Spark on YARN
To use Spark on YARN, Hadoop YARN cluster should be Docker enabled. In the remainder of this discussion, we are going to describe YARN Docker support in Apache Hadoop 3.1.0 release and beyond.
Note that YARN containerization support enables applications to optionally run inside docker containers. That is, on the same Hadoop cluster, one can run applications within Docker and without Docker side-by-side.
Running Dockerized Apps on YARN
Refer to the documentation for launching applications using Docker containers to enable Docker support on YARN and to understand Docker Image requirements. During application submission, the following two settings are required to be specified
- YARN_CONTAINER_RUNTIME_TYPE=docker
- YARN_CONTAINER_RUNTIME_DOCKER_IMAGE=<docker image>
That is all it takes to run any YARN app within a docker container !
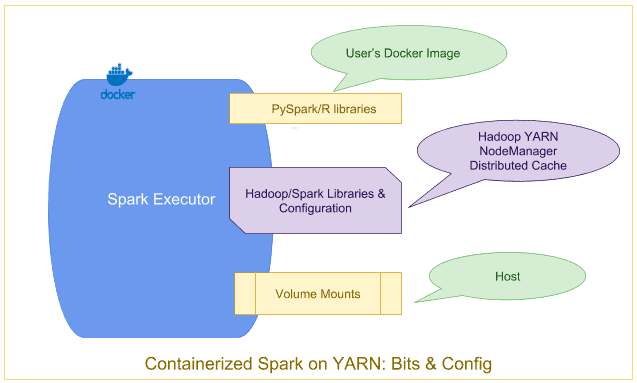
Containerized Spark: Bits & Config
The base Spark & Hadoop libraries and related configuration, installed on the gateway hosts, are distributed automatically to all the Spark hosts in the cluster through Hadoop’s Distributed Cache mechanism and mounted into the docker containers automatically by YARN.
In addition, any binaries (–files, –jars, etc) explicitly included by user at application submission, are also made available via distributed cache.
Spark Configurations
yarn client mode
Typically used through spark-shell, in the Spark client mode, the driver runs within the submission client’s JVM on gateway machine.
As part of SparkContext initialization at driver, the YARN application is submitted. The ApplicationMaster in yarn-client mode is a proxy for forwarding YARN allocation requests, container status, etc from/to driver.
In this mode, the spark driver runs on the gateway hosts as a java process and not within a YARN container. Hence, specifying any driver specific yarn configuration to use docker or docker images will not take effect. Only spark executors will run within docker containers.

During submission, deploy mode is specified as client using –deploy-mode=client
and the executor’s container configurations through environment variables as
[Settings for Executors]
spark.executorEnv.YARN_CONTAINER_RUNTIME_TYPE=docker spark.executorEnv.YARN_CONTAINER_RUNTIME_DOCKER_IMAGE=<spark executor’s docker-image> spark.executorEnv.YARN_CONTAINER_RUNTIME_DOCKER_MOUNTS=<any volume mounts needed by the
spark application>
yarn cluster mode
In the ‘classic’ distributed-application mode, a user submits a Spark job to be executed on the Hadoop cluster, which is scheduled/executed by YARN. The Application Master hosts the Spark Driver which is launched on the cluster within a docker container
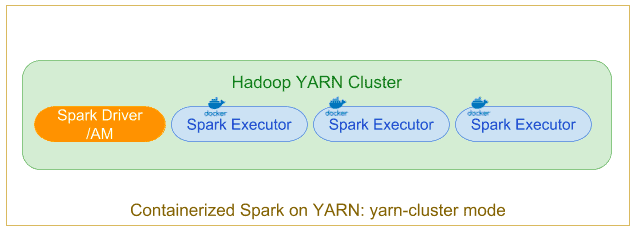
Specify deploy mode as cluster using –deploy-mode=cluster and along with the executor’s container configurations for docker, the driver/app master’s docker configurations can be set through environment variables during submission. Note that the driver’s docker image can be customized/different from the executor’s image
[Additional settings for Driver]
spark.yarn.appMasterEnv.YARN_CONTAINER_RUNTIME_TYPE=docker spark.yarn.appMasterEnv.YARN_CONTAINER_RUNTIME_DOCKER_IMAGE=<docker-image> spark.yarn.appMasterEnv.YARN_CONTAINER_RUNTIME_DOCKER_MOUNTS=/etc/passwd:/etc/passwd:ro
In the remainder of this post, we will only be showcasing yarn-client mode. But to use the examples in yarn-cluster mode, you simply have to use the additional settings above.
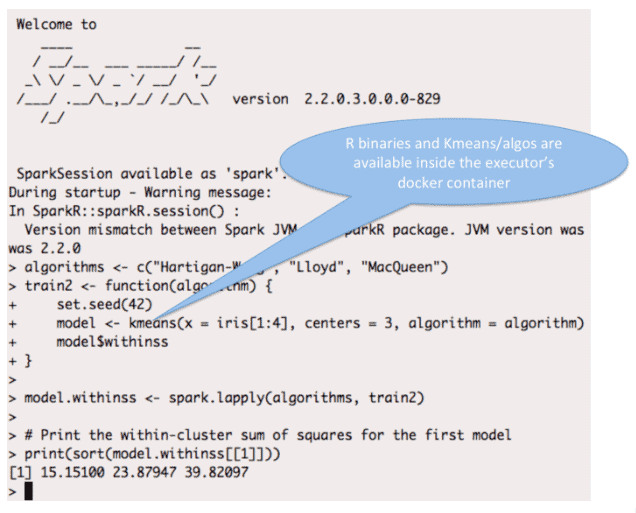
Spark-R Example
Here is an example of using Spark-R (YARN client mode) with a docker image which includes the R binary and the necessary R packages ( instead of installing these on the host)
SparkR Shell
/usr/hdp/current/spark2-client/bin/sparkR --master yarn --conf spark.executorEnv.YARN_CONTAINER_RUNTIME_TYPE=docker --conf spark.executorEnv.YARN_CONTAINER_RUNTIME_DOCKER_IMAGE=spark-r-demo --conf spark.executorEnv.YARN_CONTAINER_RUNTIME_DOCKER_MOUNTS=/etc/passwd:/etc/passwd:ro
Dockerfile

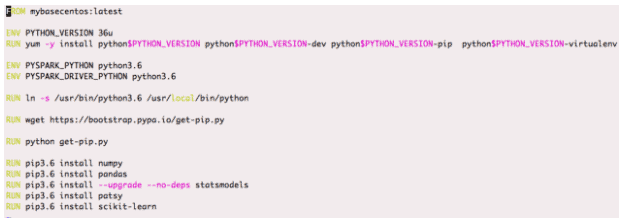
PySpark Example
The below example shows how you can use PySpark (YARN client mode) with Python3 (which is part of the Docker image and not installed on the executor host) to run OLS linear regression for each group using statsmodels with all the dependencies isolated through the docker image.
Python version can be customized using the PYSPARK_DRIVER_PYTHON and PYSPARK_PYTHON env variables on the Spark driver and executor respectively
PYSPARK_DRIVER_PYTHON=python3.6 PYSPARK_PYTHON=python3.6 pyspark --master yarn --conf
spark.executorEnv.YARN_CONTAINER_RUNTIME_TYPE=docker --conf spark.executorEnv.
YARN_CONTAINER_RUNTIME_DOCKER_IMAGE=pandas-demo --conf spark.executorEnv.
YARN_CONTAINER_RUNTIME_DOCKER_MOUNTS=/etc/passwd:/etc/passwd:ro

Dockerfile
Containerized Spark Applications through Zeppelin
To run containerized Spark through Zeppelin, one should configure the Docker image, the runtime volume mounts and the network as shown below in Zeppelin Interpreter settings under User(eg: admin)->Interpreter in Zeppelin UI.
Configuring Livy Interpreter
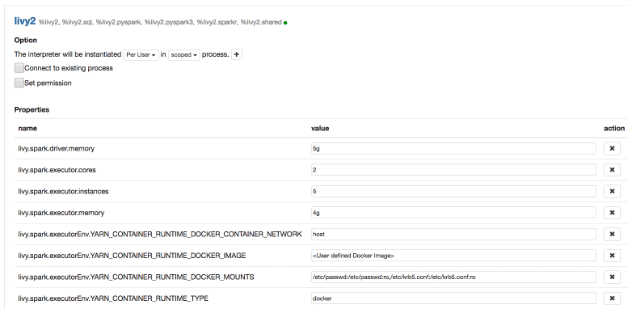
Similarly you can configure Docker images/volumes etc for other interpreters in Zeppelin.
You need to restart the interpreter(s) for these settings to take effect and can submit spark applications as before in Zeppelin to launch them through docker containers.
Conclusion
In this post, we have described how users can run containerized Spark applications on YARN side by side in Docker containers with customized python versions/libraries and R packages.
These dependencies no longer need to be installed on all the hosts in the Spark cluster and users can focus on running/tuning the application instead of tweaking the environment in which the application needs to run.
Spark on docker in Apache YARN supports both client and cluster mode and has been tested with Livy/Zeppelin as well.
Docker also provides network isolation, where applicable, allowing for more sophisticated cluster configuration/customization. Currently, only “host” network mode i.e YARN_CONTAINER_RUNTIME_DOCKER_CONTAINER_NETWORK=host is supported and there is ongoing effort to optimize support for other network modes as part of SPARK-23717.
Thanks to Yanbo Liang for valuable inputs and feedback on this effort. Thanks to Bikas Saha and Vinod Kumar Vavilapalli for ideation and different approaches.
LEARN MORE ABOUT HADOOP 3:
- First-Class Support for Long Running Services on Apache Hadoop YARN
- How Apache Hadoop 3 Adds Value Over Apache Hadoop 2
- Apache Hadoop 3.1.0 released. And a look back!
- Apache Hadoop 3.1 – A Giant Leap for Big Data
- Trying Out Containerized Applications on Apache Hadoop YARN 3.1
Editor's Choice

