

This blog post was published on Hortonworks.com before the merger with Cloudera. Some links, resources, or references may no longer be accurate.
This is the third in a series of data engineering blogs that we plan to publish. The first blog outlined the data science and data engineering capabilities of Hortonworks Data Platform.
Motivation
Apache Spark is becoming the de-facto processing framework for all kinds of complex processing including ETL, LOB business data processing and machine learning. This is because of the simple and intuitive APIs for common data processing operations and deep integration with popular languages like Java, Scala, Python and R. Increasingly, it’s also being adopted for continuous processing scenarios using the Structured Streaming APIs that make it really easy to write robust streaming applications.
The runaway popularity of Spark in enabling the creation of data processing jobs has enabled a huge productivity boost for developers, resulting in the creation of multiple jobs and dependent data pipelines that address a wide variety of business scenarios. While that is excellent in terms of achieving business value, it also creates the need to manage and govern all these data processing jobs and pipelines. For data governance and lineage, it’s crucial to record the Spark jobs that accessed and/or modified datasets. Commonly, data engineering teams do not work in isolation and consume data sets from wide variety of sources, resulting in explicit or implicit chaining of dependent data processing Spark jobs. Tracking and auditing the lineage of data as it flows through these pipelines is extremely important for enterprise data governance.
The current climate with heightened security awareness and new compliance regulations like GDPR make it imperative for enterprises to track and audit data access and data transformation lineage, as data flows through their enterprise Spark jobs.
Apache Spark and Atlas Integration
We have implemented a Spark Atlas Connector (SAC) in order to solve the above scenario of tracking lineage and provenance of data access via Spark jobs. Apache Atlas is a popular open source framework to recording and tracking lineage that already has integrations with other projects like Apache Hive, Storm, HDFS, HBase etc. Hence it made sense to integrate with Atlas first and other frameworks could be supported.
Lineage tracking has to be transparent, such that its recorded without user/developer action, or else there’s the risk of user inaction resulting in provenance gaps. For a rich framework, like Apache Spark, lineage tracking has to be comprehensive, so as to cover all functional scenarios like batch jobs, SQL queries, stream processing, machine learning as well as across all supported languages like Scala, Python and R. SAC covers all these scenarios as shown in the following lineage information captured via SAC as presented by a screenshot from the Atlas UI.
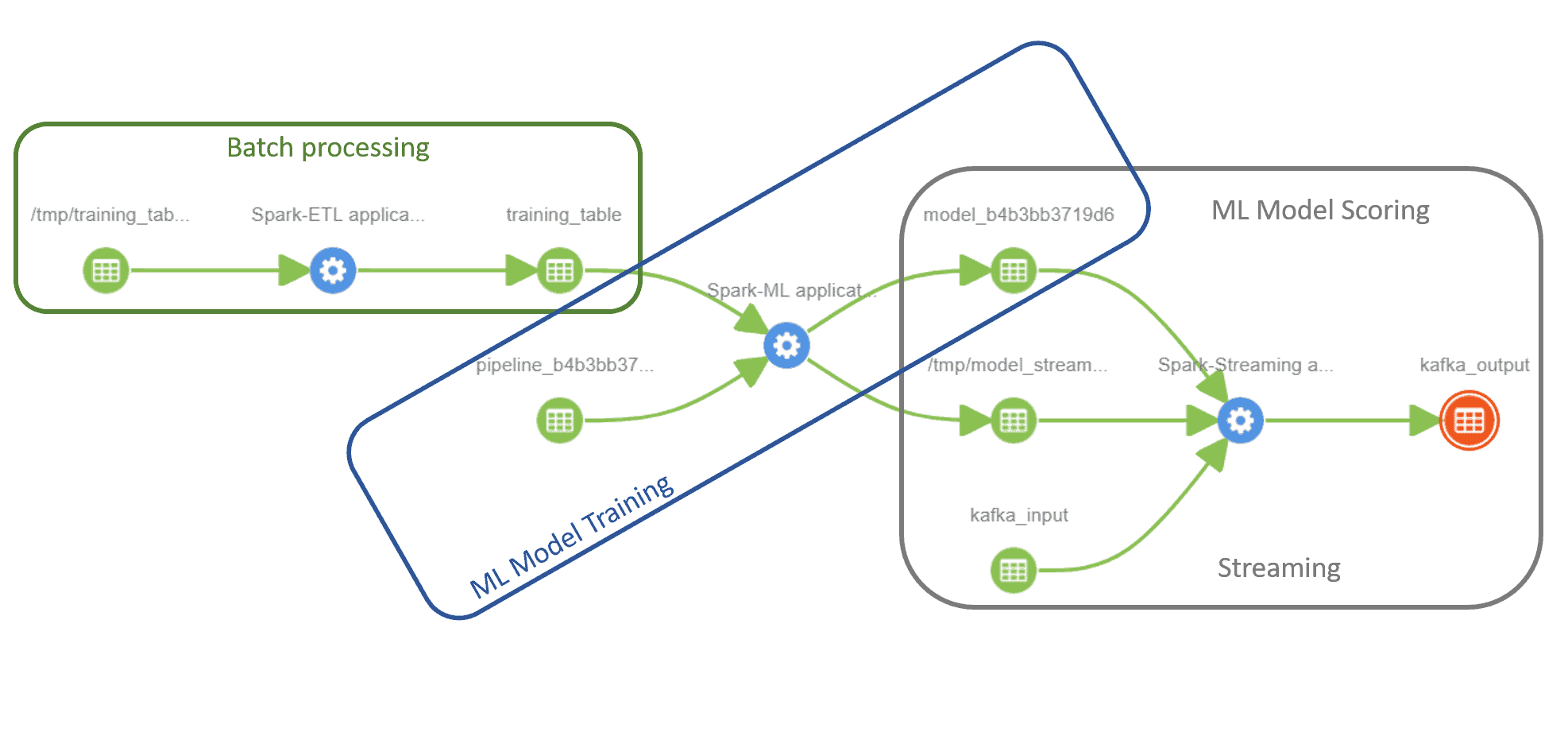
Here we see an end to end sequence of applications written using Apache Spark (potentially by different teams) that covers the multitude of scenarios without any user intervention. The connector has to be configured and added to the job by the admin. To start off, it captures an ETL job converting raw data from HDFS into a relation SparkSQL table. Then a machine learning job reads data from that table and uses a SparkML pipeline to train a SparkML model thats stored in HDFS. That SparkML model is used by a Spark structured streaming job to continuously score input data from a Kafka topic and write the output to a different Kafka topic. Thus we can see how SAC is capturing this rich information that goes much beyond simply data governance. It’s capturing the implicit enterprise job dependency graph that could be analysed for a variety of actionable results, such as work duplication.
The integration with SparkML to automatically capture ML models as provenance entities is an industry leading feature. It automatically tracks models being trained via Spark and also those models being used for scoring. This is extremely useful for auditing machine learning scenarios – e.g. if we need to figure out how we trained a model that we used to score a specific record that is being audited for a given compliance requirement.
Spark Atlas Connector is under active development and close to being production ready. We encourage users to try it out for themselves, explore the value and provide us with feedback.
The code for the Spark Atlas Connector is open source and available here.
Editor's Choice

