![Distributed Pricing Engine using Dockerized Spark on YARN w/ HDP 3.0 [Part 3/4]](/wp-content/themes/cloudera/assets/images/default-banner/GettyImages-1287640296-1382x400.jpg)

This blog post was published on Hortonworks.com before the merger with Cloudera. Some links, resources, or references may no longer be accurate.
This is the 3nd blog in the series (see part 1, part 2) where we will walk through the tech stack and prepare the environment.
The entire infrastructure is provisioned on OpenStack private cloud using Cloudbreak 2.7.0 which first automates the installation of Docker CE 18.03 on CentOS 7.4 VMs and then the installation of HDP 3.0 cluster with Apache Hadoop 3.1 and Apache Spark 2.3 using the new shiny Apache Ambari 2.7.0
To Try This at Home
Ensure you have access to a Hortonworks Cloudbreak 2.7.0 instance. Please refer to the documentation to meet the prerequisites and setup credentials for the desired cloud provider.
Clone this repo
Update the following as desired:
- Cloudbreak cluster definition
- Ambari cluster blueprint
Now upload the following to your Cloudbreak instance:
- Ambari Blueprint
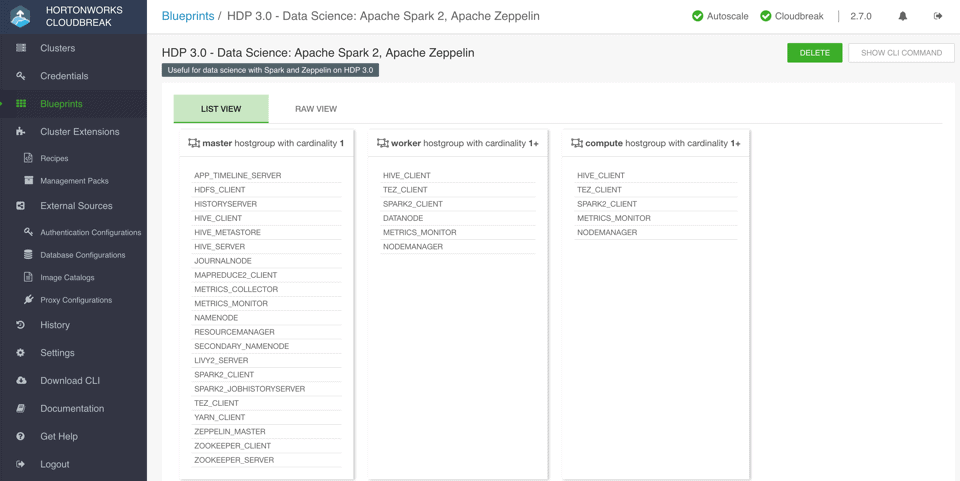
- Recipe to install Docker CE with custom Docker daemon settings:
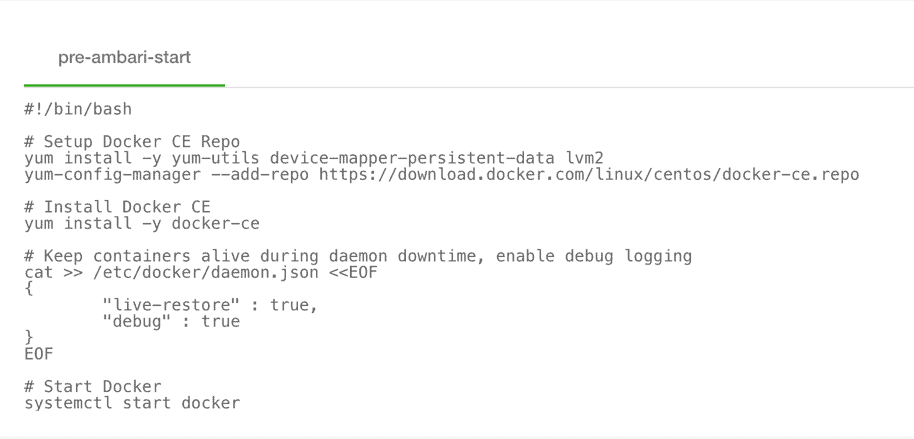
- Now execute the following using Cloudbreak CLI to provision the cluster:
cb cluster create —cli–input–json <cluster-def.json> —name <cluster-name>
This will first instantiate a cluster using the cluster definition JSON and the referenced base image, download packages for Ambari and HDP, install Docker (a pre-requisite to running Dockerized apps on YARN) and setup the DB for Ambari and Hive using the recipes and then install HDP 3 using the Ambari blueprint.
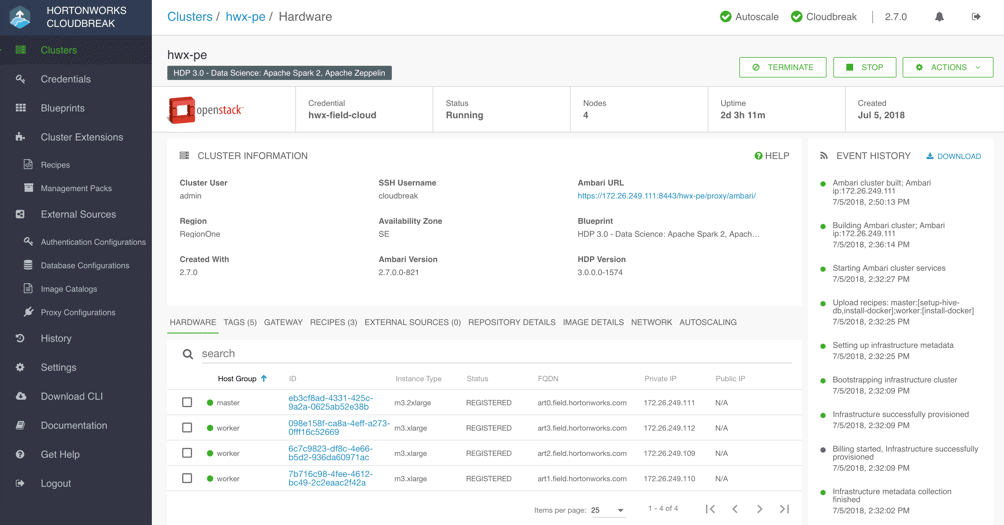
Once the cluster is built, you should be able to log into Ambari to verify
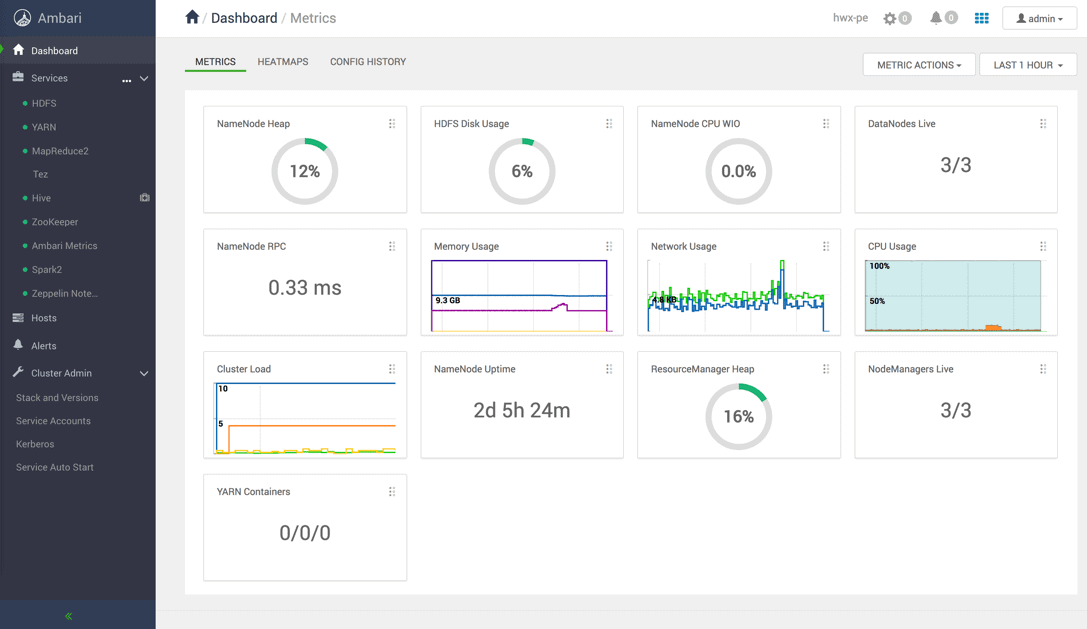
Now, we will configure YARN Node Manager to run LinuxContainerExecutor in non-secure mode, just for demonstration purpose, so that all Docker containers scheduled by YARN will run as ‘nobody’ user. Kerberized cluster with cgroups enabled is recommended for production.
Enable Docker Runtime for YARN
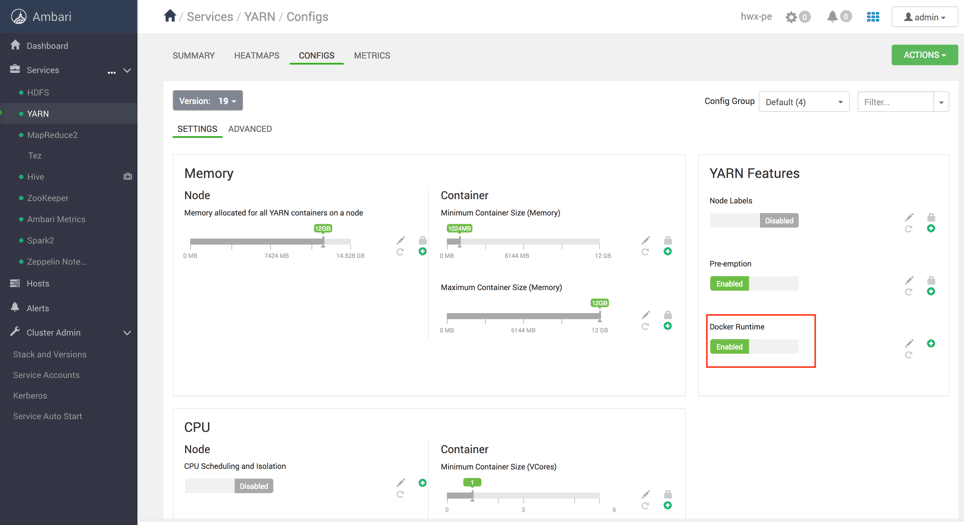
Update yarn-site.xml and container-executor.cfg as follows:
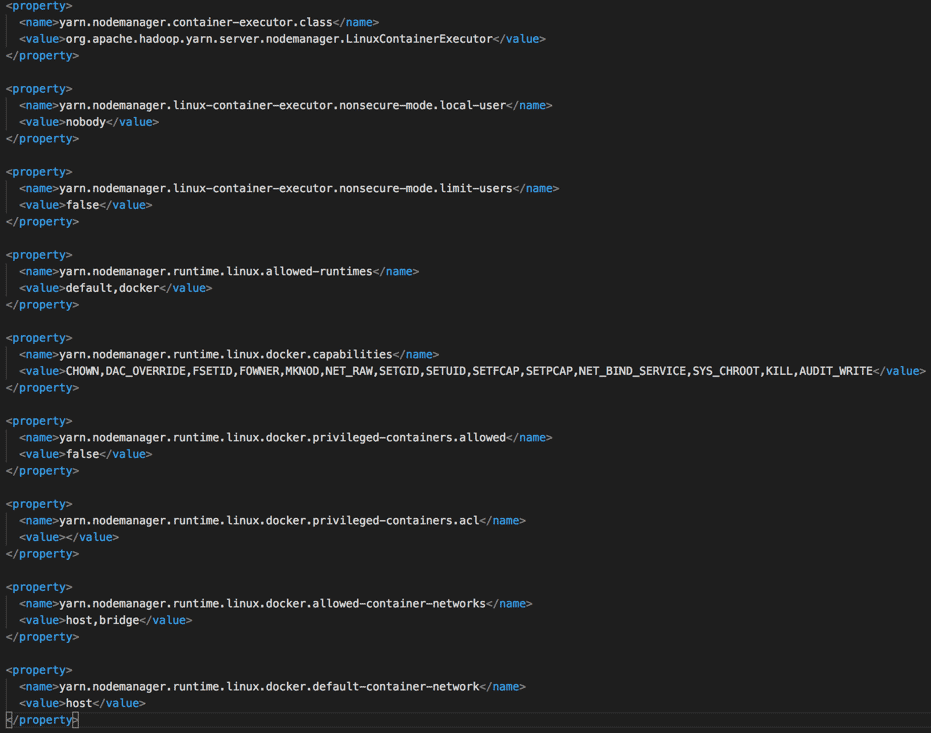
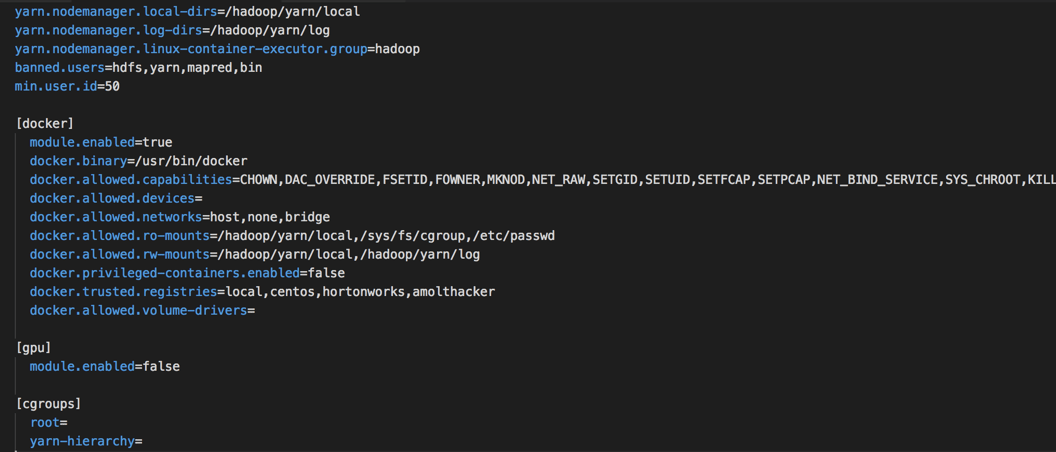 A few configurations to note here:
A few configurations to note here:
- Setting nodemanager.container-exexutor.class to use LinuxContainerExecutor
- Setting user.id to a value (50) less than user id of user ‘nobody’ (99)
- Mounting /etc/passwd on read-only mode into the Docker containers to expose the spark user
- Adding requisite Docker registries to the trusted list
Now restart YARN
We are now ready to simulate pricing of instruments which we will take a look at in the final blog of the series, you can find it here!
Editor's Choice

