

This blog post was published on Hortonworks.com before the merger with Cloudera. Some links, resources, or references may no longer be accurate.
We are excited to announce the immediate availability of HDPSearch 4.0. As you are aware, HDP Search offers a performant, scalable, and fault-tolerant enterprise search solution. With HDP Search 4.0, we have added the following new features:
- Upgraded Apache Solr to Solr 7.4. Apache Solr 7.x offers several new features such as autoscaling, replication modes, etc.
- Updated Apache Hadoop Solr connectors to support HDP 3.0
-
- HDFS (updated to support Hadoop 3.1.0)
- Apache Hive (updated to support Apache Hive 3.0)
- Apache Spark (updated to support Apache Spark 2.3.1)
Note: HDP Search 4.0 will only work with HDP 3.0 because the connectors have been updated to support the corresponding component versions in HDP 3.0.
Solr 7.x includes the following news features:
- Autoscaling – Today, cluster management (provisioning, splitting shards, moving replicas, etc.) is largely manual. With the auto-scaling feature, you can automate collection and data/load redistribution operations via autoscaling APIs. It aims to keep the SolrCloud cluster balanced and stable in the face of various cluster change events. This balance is achieved by satisfying a set of user-configurable rules and sorting preferences to select the target of cluster management operations automatically on cluster events.
- Replication Modes – Two new types of replicas have been added, named TLOG & PULL to provide flexibility to the existing SolrCloud replica model.
Please refer to the Apache Solr 7.4 reference guide for more information on the new Solr 7.x features.
Below shows how you can use HDP Search 4.0 with the updated spark connector to write and read data from Solr:
Step 1: Writing data to Solr
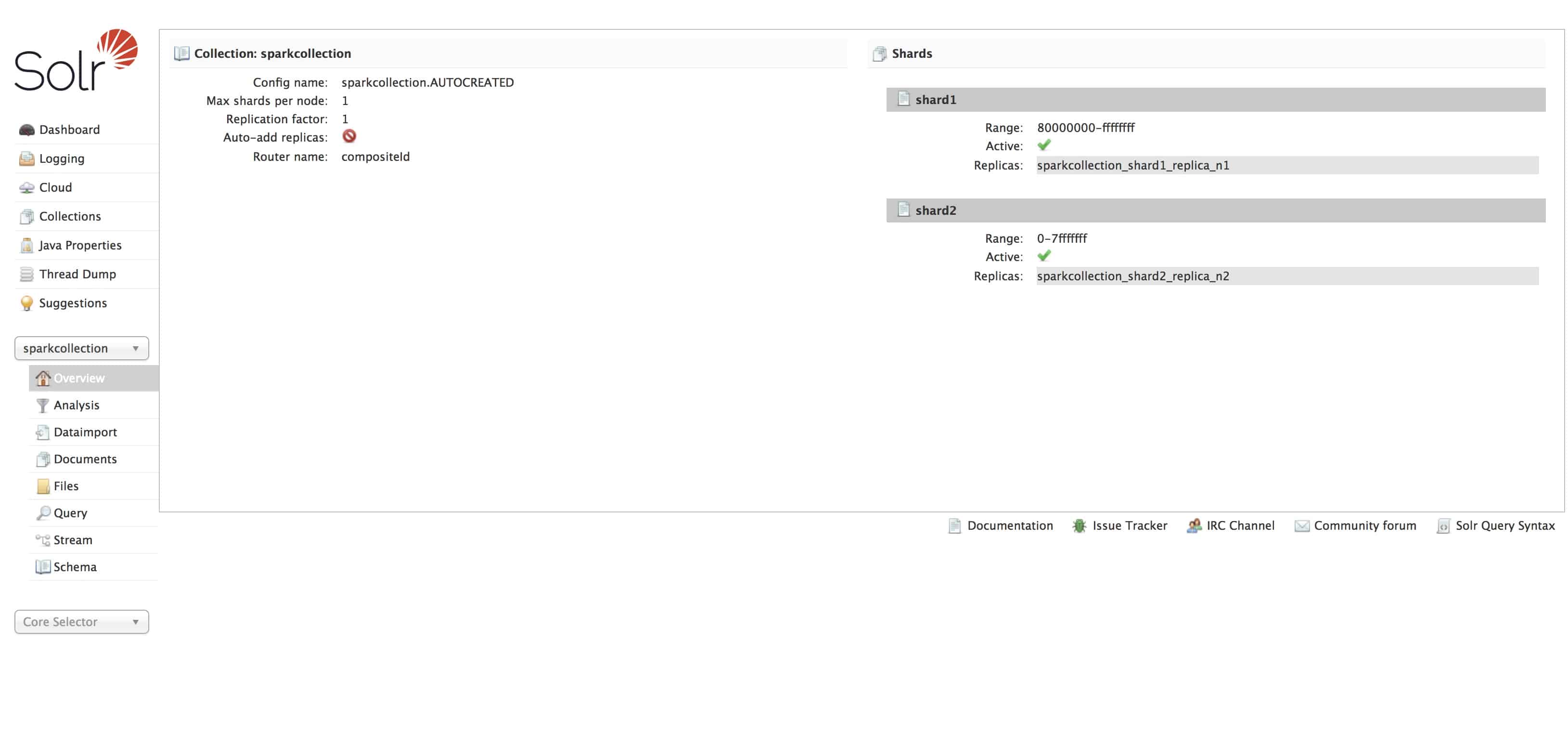
Below curl command will create a spark collection named “sparkcollection” with 2 shards and 1 replica as seen in the Solr UI below:
curl -X GET “http://<solr_host>:8983/solr/admin/collections?action=CREATE&name=sparkcollection&numShards=2&replicationFactor=1”
The CSV file used here is located here. Move the CSV file to the /tmp HDFS directory and read it as a Spark DataFrame as shown below.
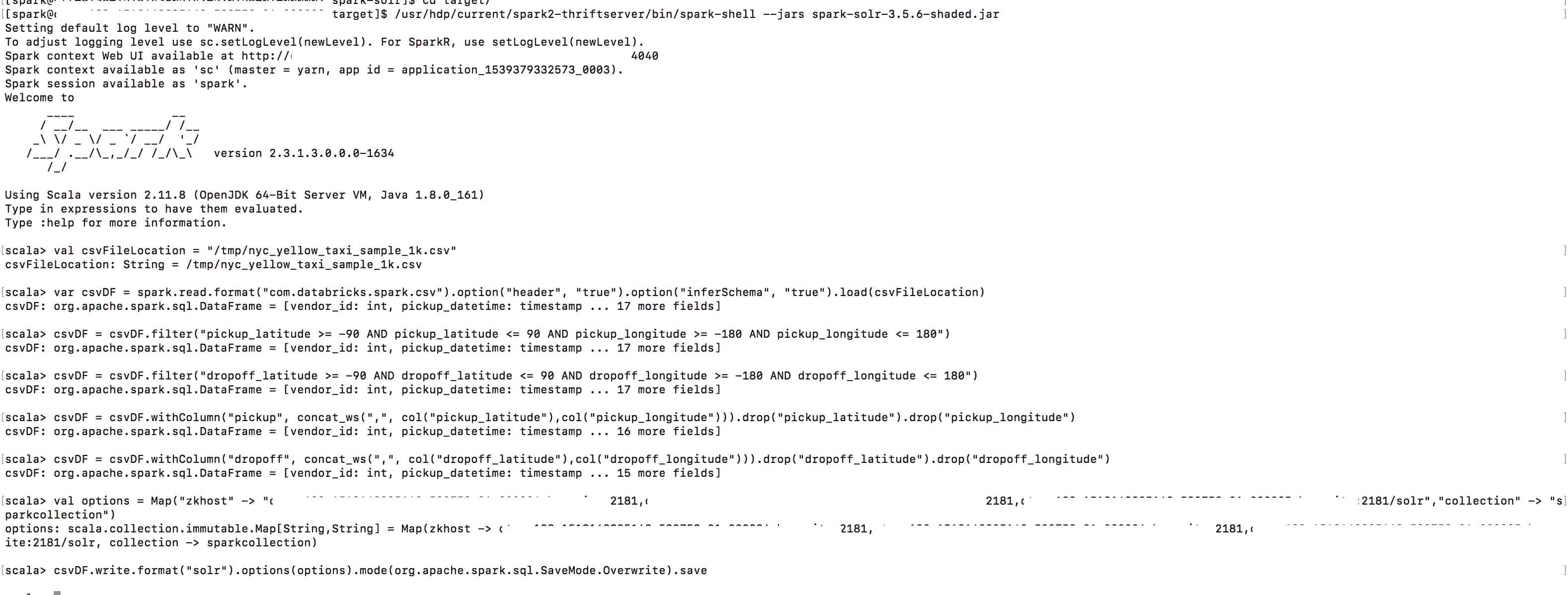
Index this data to Solr using the command: http://<solr_host>:8983/solr/sparkcollection/update?commit=true
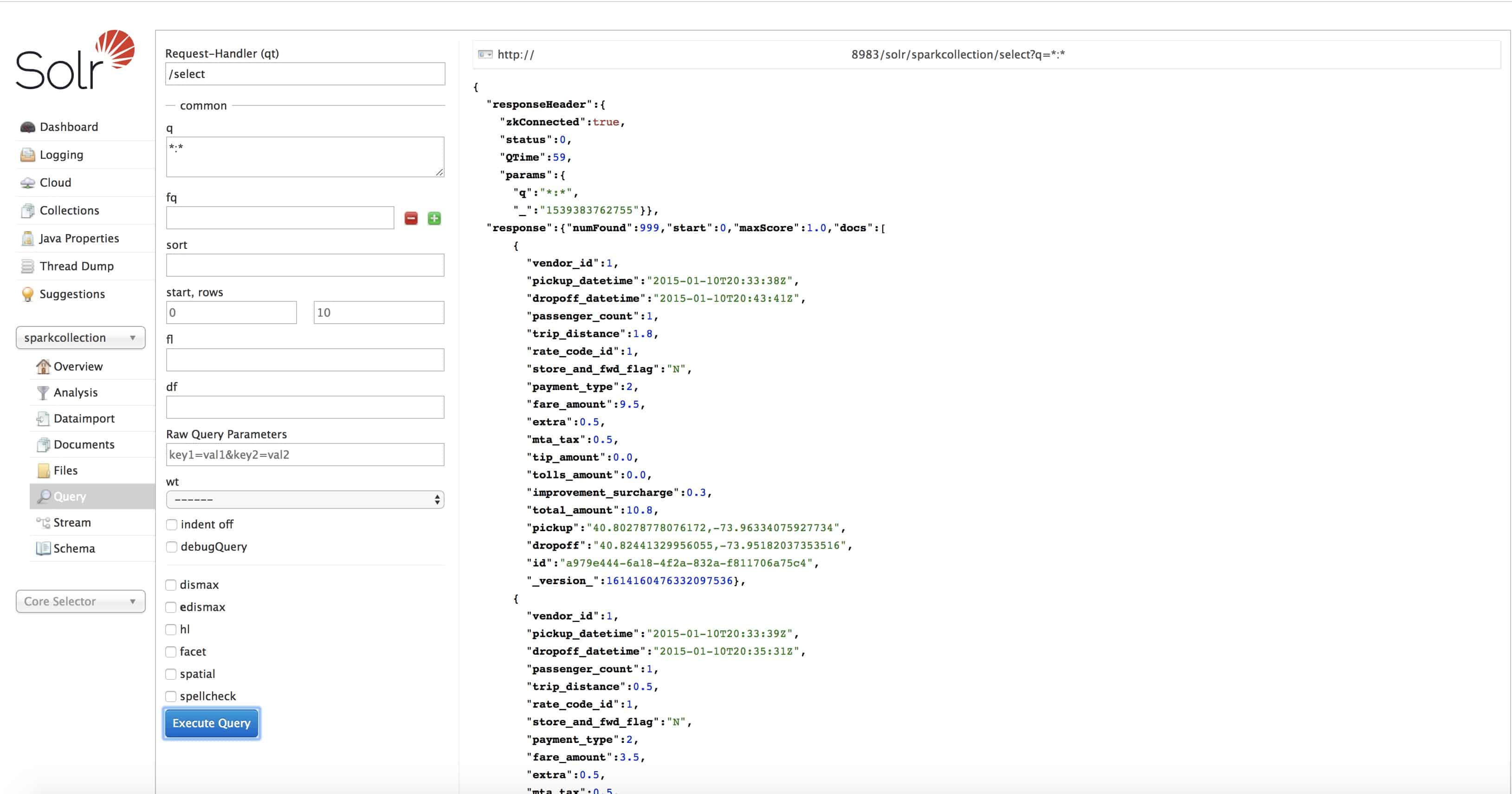
Run a query on Solr UI to validate the setup:
*:* returns all 999 docs indexed
Query for a particular pickup location returns one document
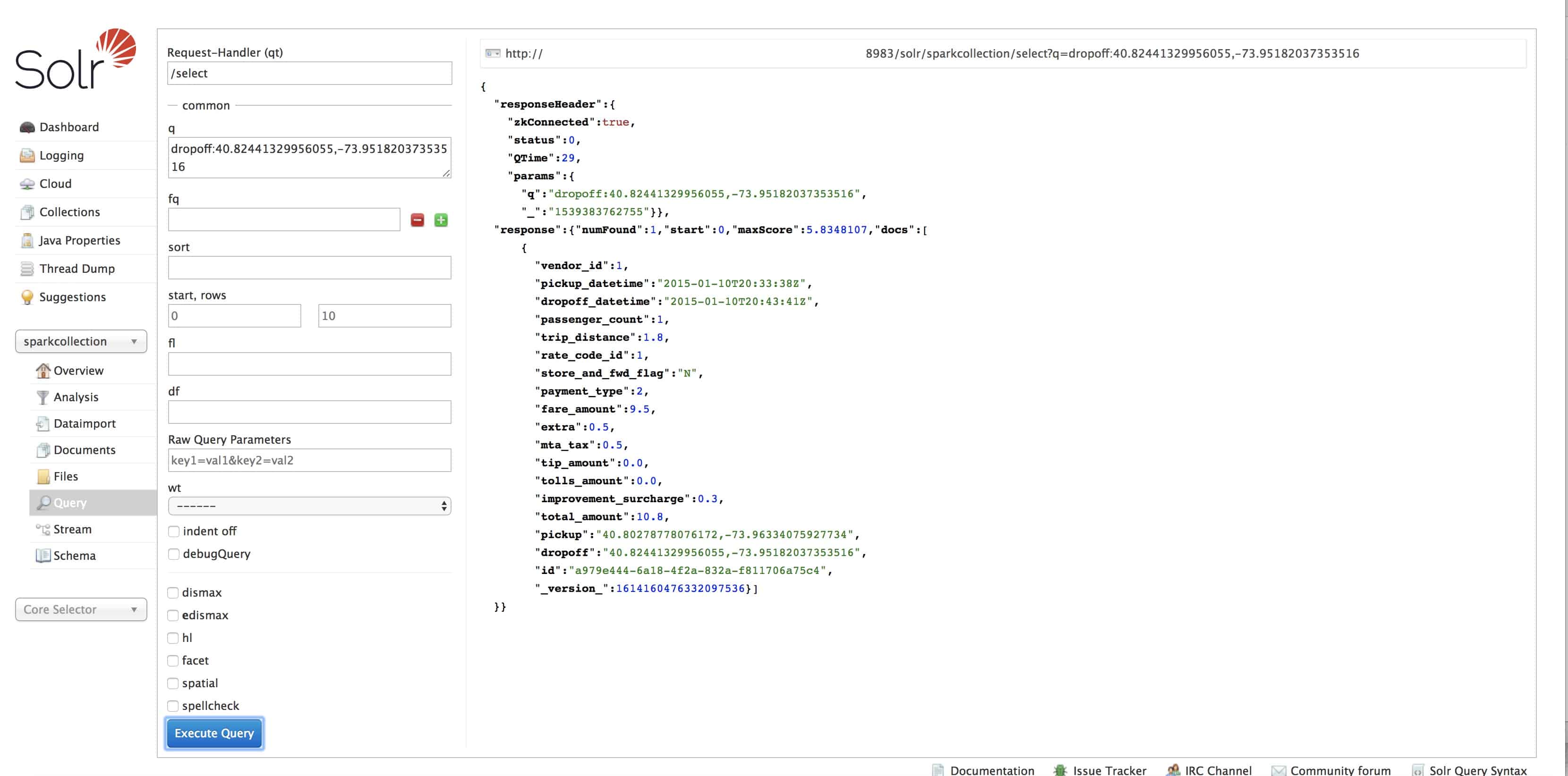
Step 2: Reading data from Solr
Read from Spark (tip and fare):

Read from spark (total amount and toll amount)
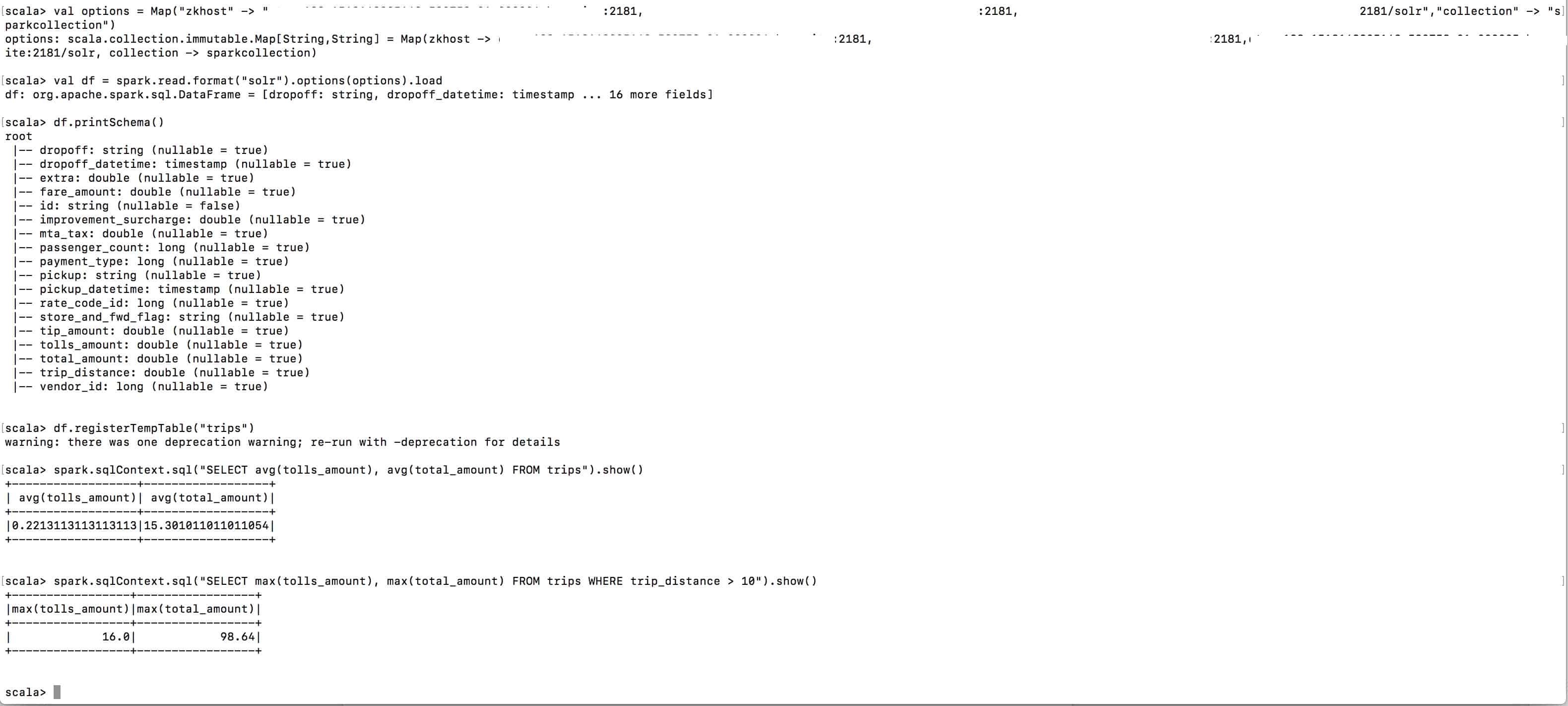
Similarly, you can index and search data stored in Hive and HDFS as well by using the corresponding connectors.
Use the below resources to learn more about HDPSearch 4.0:
Please stay tuned for future blogs on HDP Search!
Editor's Choice

