

This blog post was published on Hortonworks.com before the merger with Cloudera. Some links, resources, or references may no longer be accurate.
Computers are getting smarter and we are not.
–Tim Berners Lee, Web Developer
{kind=link}
Google, Amazon and Netflix have conditioned us. As consumers, we expect intelligent applications that predict, suggest and anticipate our every move. We want them to sift through the millions of possibilities and suggest just a few that suit our needs. We want applications that take us on a personalized journey through a world of endless possibilities.
These personalized journeys require systems to store and make sense of huge data volumes in an acceptable amount of time. This has been Hadoop’s strong suit since day one.
Delivering the journey also requires applications to directly integrate with deep analytics. This remains a challenge as most operational systems run outside Hadoop, placing operational data and analytics in separate silos.

Technologies like Apache Hadoop YARN and Apache Slider are beginning to break down these silos. YARN gives Hadoop resource isolation controls that make it possible to deeply analyze application data in-place while providing answers in an acceptable time frame. And Apache Slider makes it easy to deploy long-running operational systems into Hadoop.
YARN is the architectural center of Hadoop that allows multiple data processing engines such as interactive SQL, real-time streaming, data science and batch processing to handle data stored in a single platform, unlocking an entirely new approach to analytics. This provides a seamless integration of operational and analytical systems and a foundation on which the enterprise can build out a Modern Data Architecture (MDA).

The State of The Art in Hadoop
It is possible to blend operational and analytics together in Hadoop today, and in fact we see many of our customers doing it.
The pieces you need are already in Hadoop:
- Apache HBase is the NoSQL database for Hadoop and is great at fast updates and low latency data access.
- Apache Phoenix (pioneered by Salesforce) is a SQL skin for data in HBase. Phoenix is already investigating integration with transaction managers like Tephra (from Cask).
- Apache Hive is the de-facto SQL engine for Hadoop providing the deepest SQL analytics and supporting both batch and interactive query patterns. See our recent Stinger.Next post for advances such as Hive LLAP.
We see our customers using these parts today to build applications with deep analytics, for example a very common pattern we see includes:
- Using HBase as the online operational data store for fast updates on hot data such as current partition for the hour, day etc.
- Executing operational queries directly against HBase using Apache Phoenix.
- Aging data in HBase to Hive tables using standard ETL patterns.
- Performing deep SQL analytics using Hive
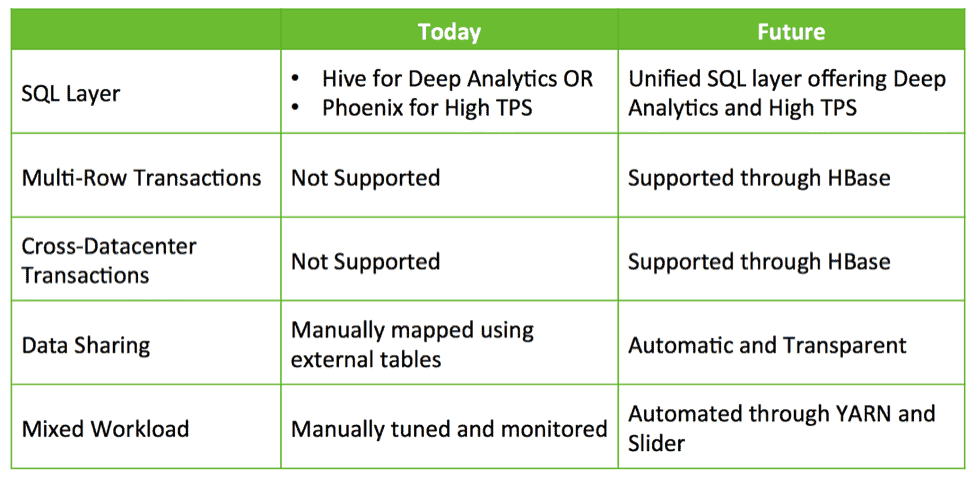
This works but it creates a number of complexities for developers. For example:
- Which SQL interface do I use and when? Do I use Hive which offers deep SQL but low TPS? Or do I use Phoenix with high TPS and basic SQL? Or do I use both?
- If I use both, how do I share data between Hive and HBase?
- How do I tune my cluster so that I can successfully co-locate HBase and Hive while meeting my SLAs?
These questions suggest deeper integration is needed to simplify building applications with deep analytics on Hadoop.
HBase and Hive: Better Together
What opportunities exist for deeper integration? Currently, customers are putting together solutions leveraging HBase, Phoenix, Hive etc. to build bespoke a closed-loop system for operational data and SQL analytics. We feel there is an opportunity to provide out-of-the-box integration with ease of use and additional capabilities such as transactions, cross datacenter failover etc.
Hive, HBase and Phoenix all have very active community of developers and are used in production in countless organizations. These are solid, proven operational capabilities that can be the foundation and future of transaction processing on Hadoop.
So, using the same approach as the successful Stinger Initiative, Hortonworks looks to invest further in these core projects and build momentum as opposed to abandoning them and starting over. We plan to invest in improvements that further an integrated operational and analytical experience via a tightly integrated Hive and HBase. This addresses real and interesting use cases in a way that preserves investments and drives real value for customers.
We see four major development areas to help realize the vision of intelligent applications:
1. A Unified SQL Layer with Hive
Developers building SQL applications should not have to choose between different SQL solutions, each with its own strengths and weakness. We envision a unified SQL layer, enabled by Hive’s support for SQL:2011, that transparently uses the appropriate engine based on the query access pattern.
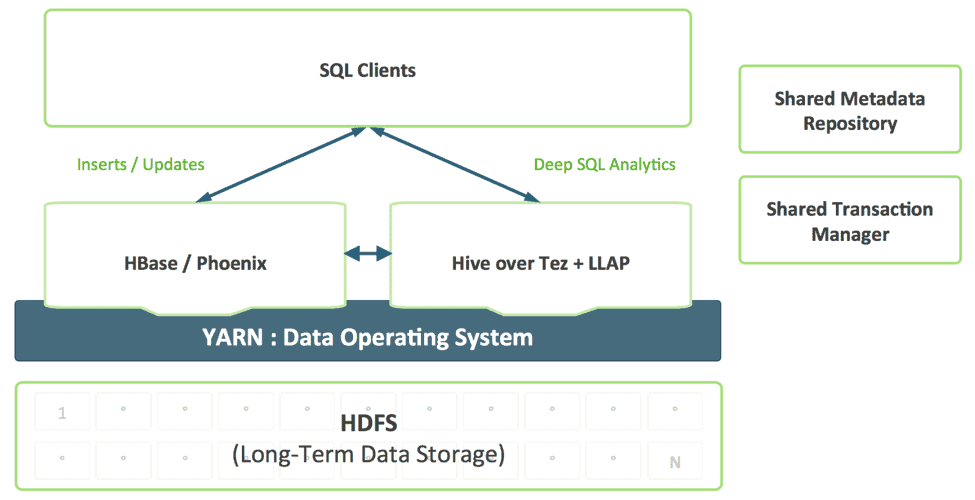
This combination provides a single SQL dialect and single connector. Data architects and DBAs can determine where data should be stored based on usage patterns without burdening user applications with the need to connect to multiple systems.
2. Improving HBase as an Operational Store
HBase is rapidly maturing as an operational store and will be able to take on more and more demanding workloads. In the past year, HBase has added a SQL interface, secondary indexing and high availability. These features will continue to mature, and in addition, HBase will add additional enterprise-grade features like multi-table, cross-datacenter transactions and more.
Projects like Omid (Yahoo), Tephra (
3. Shared Metadata Catalog and Transaction Manager
Data created in HBase should be automatically visible in Hive and vice-versa. This capability renders data sharing between online and analytical completely trivial. A shared transaction manager allows Hive’s new ACID feature and multi-table HBase transactions to work together seamlessly.
4. YARN-enabled Mixed Workload Support
Today, customers typically deploy HBase and Hive in separate clusters. Developing a closed-loop analytics system requires effective combination of operational and analytical workloads in a multi-tenant manner. With YARN we can effectively create a single-system by leveraging resource isolation and workload management primitives in YARN to support different forms of access to data. Slider makes use of these when it deploys HBase into YARN, while Hive LLAP & Tez are native YARN applications, thereby simplifying the process of running a closed-loop analytical system according to a predictable SLA.
Conclusion
Enterprises are using already existing technologies available in HDP such Apache HBase, Apache Hive, Apache Phoenix etc. to deal with fast updates to current data and analytics over vast array of data-sets, all stored in HDFS to effect a closed-loop analytics system. We hope to leverage the same integration patterns to provide a seamless experience for customers by making Apache HBase and Apache Hive better – better together, rather than net new technologies for users to understand and consume.
Editor's Choice

