

This blog post was published on Hortonworks.com before the merger with Cloudera. Some links, resources, or references may no longer be accurate.
Two weeks ago, we announced the GA of HDF 3.1, and to share more details about this milestone release we started the HDF 3.1 Blog Series. In this installment of the series, we’ll talk about a net new integration point between Apache NiFi and Apache Atlas.
As the latest Data-in-Motion Platform offering from Hortonworks, HDF 3.1 is complementary to HDP by providing an end-to-end Big Data solution for enterprises with a compelling user experience. In HDF 3.1, improvements were made to facilitate core enhancements and cross-component integration and operability on the platform. Advanced control and manageability are introduced to help customers easily navigate, store, secure, and consume data-in-motion to achieve faster time-to-value, cross-component transparency, and lowered operational overheads.
HDF 3.1 is a significant release which unlocks new capabilities to improve enterprise productivity. Specifically, by enabling the integration between Apache NiFi and Apache Atlas, HDF 3.1 provides better manageability and accessibility. Users can get a comprehensive cross-component lineage view at dataset level.
Prerequisites
- When HDF 3.1 – NiFi is being deployed on an HDP cluster (Atlas being deployed as part of the HDP cluster), HDP 2.6.4 is required, mostly required by Ambari
- When HDF 3.1 – NiFi is being deployed on a separate HDF cluster, managed by a separate Ambari instance, NiFi is compatible with Apache Atlas 0.8.0+ or HDP 2.6.1+
Atlas Authentication
In both aforementioned deployment scenarios, the following authentication mechanisms are supported between NiFi and Atlas:
- Atlas REST API: BASIC (username and password), SPNEGO(Kerberos) and SSL
- Kafka: SASL with GSSAPI (Kerberos), and SSL
Use Case
Let’s walk thru a use case to further understand how NiFi works in conjunction with Atlas. First of all, see the following dataflow running on the NiFi side (Fig.1). We have two ‘GenerateFlowFile’ processors (generating speed events and geo-location events correspondingly) sending data to a ‘PublishKafkaRecord’ processor. And the kafka processor makes dynamic routing decision based on the origin of the FlowFiles (speed events vs. geo-location events).
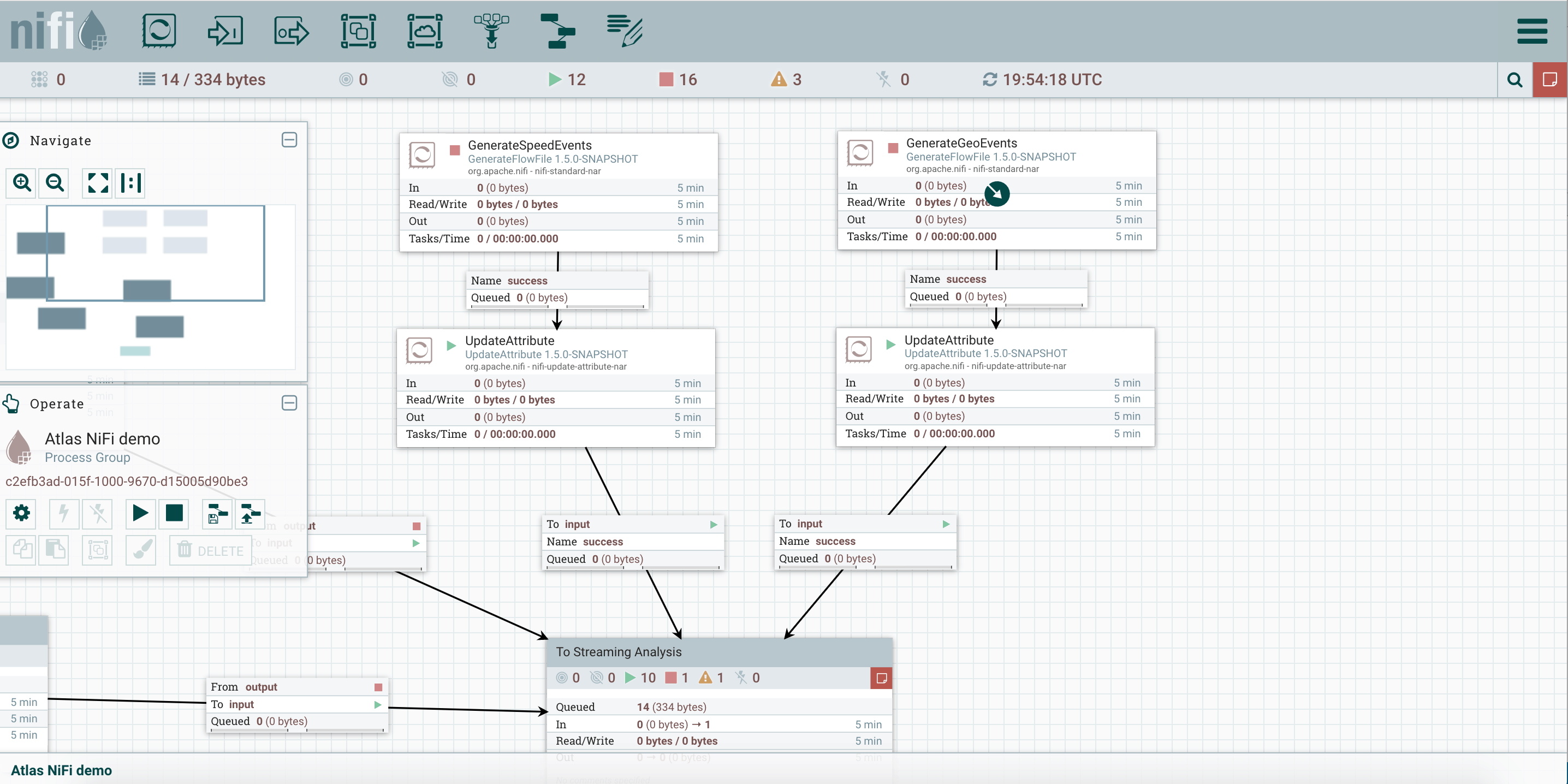
Fig.1: NiFi DataFlow
Now open go to the hamburger menu on the upper right corner, go to controller settings and then reporting tasks. You can add a ‘ReportLineageToAtlas’ reporting task there (Fig.2).
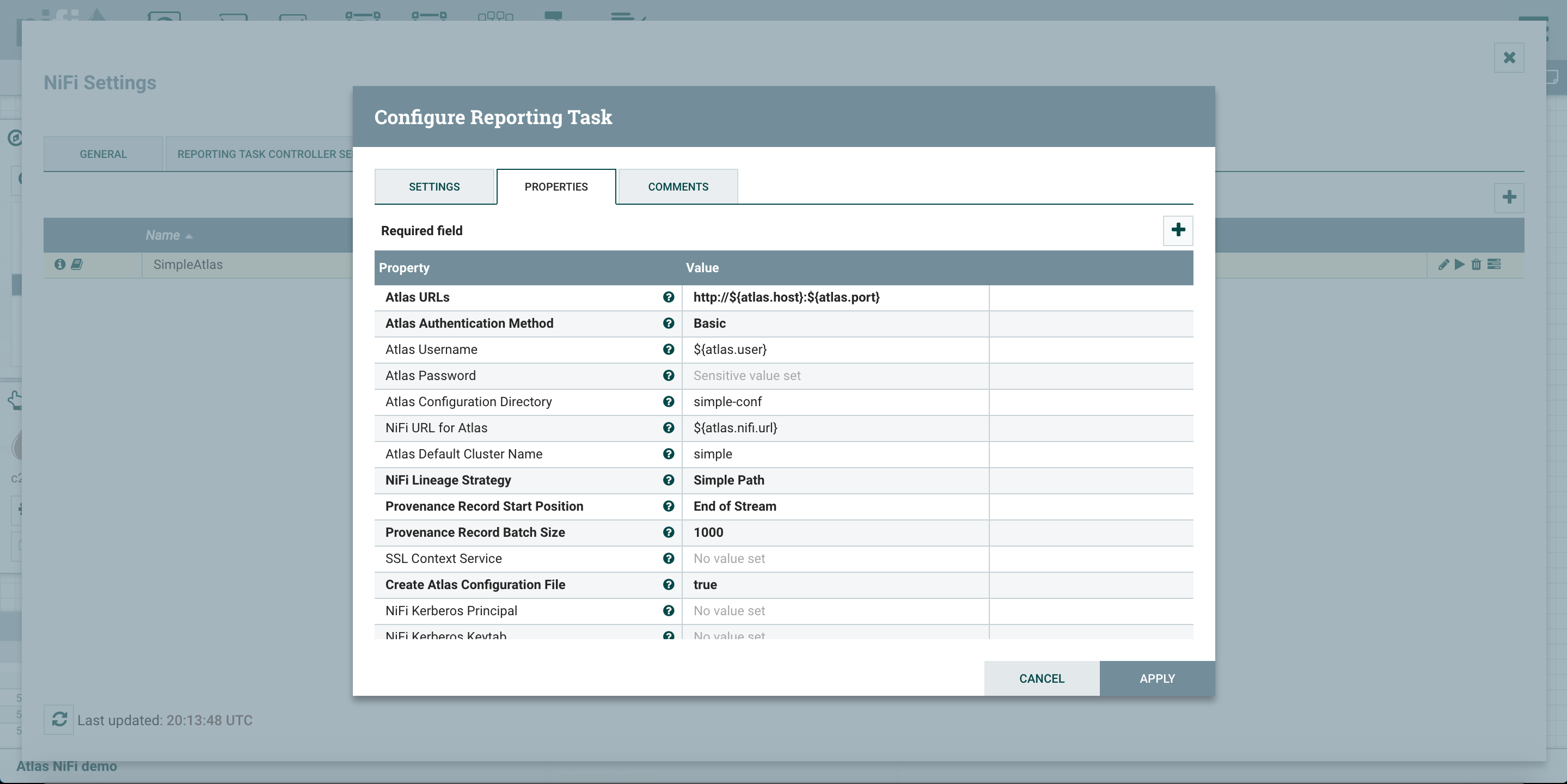
Fig.2: configure NiFi reporting task for Atlas integration
Notice that, as part of the reporting task configuration, under the ‘NiFi lineage strategy’ property, you can choose between two options:
- Simple path
- Complete path
When the simple path strategy is selected, NiFi would breakdown the entire dataflow into logical flow paths based on analyzing the processor connectivity information in the flow definition file, plus analyzing RECEIVE and SEND provenance events. Then NiFi would report the ‘flow structure’, meaning how the flow paths are connected, to Atlas, and generate a dataset level lineage view in Atlas.
When the complete path strategy is selected, in addition to analyzing the flow path connectivity information in the flow definition file and RECEIVE/SEND events, other provenance events would also be consumed in order to provide more accurate runtime information. In other words, by looking at all the provenance events along the chain (from CREATE/RECEIVE all the way to DROP), we could identify which datasets are connected to a given processor. See Fig.3 for the difference between the simple and complete path lineage strategy.
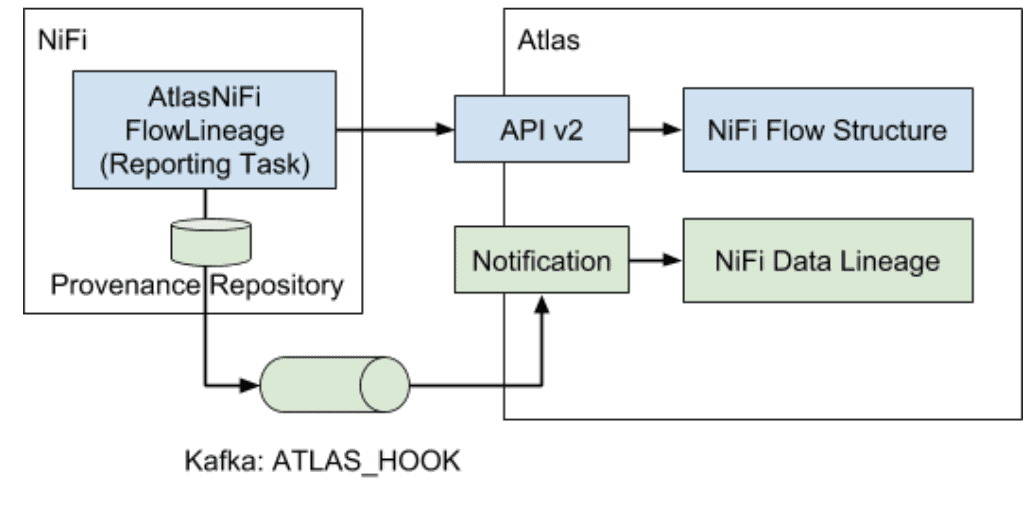
Fig.3: simple vs complete lineage strategy
In the aforementioned use case scenario, let’s try to compare the difference between the two lineage strategies.
First of all, search for kafka topics in Atlas (Fig.4), and we can see two results: speed-topic and geo-topic. By looking at the corresponding NiFi flow, it is clear that all the messages persisted in the speed-topic came from the ‘GenerateSpeedEvents’ processor, and all the messages persisted in the geo-topic came from the ‘GenerateGeoEvents’ processor. A one-on-one mapping is honored between the two ‘GenerateFlowFile’ processors and the two kafka topics.
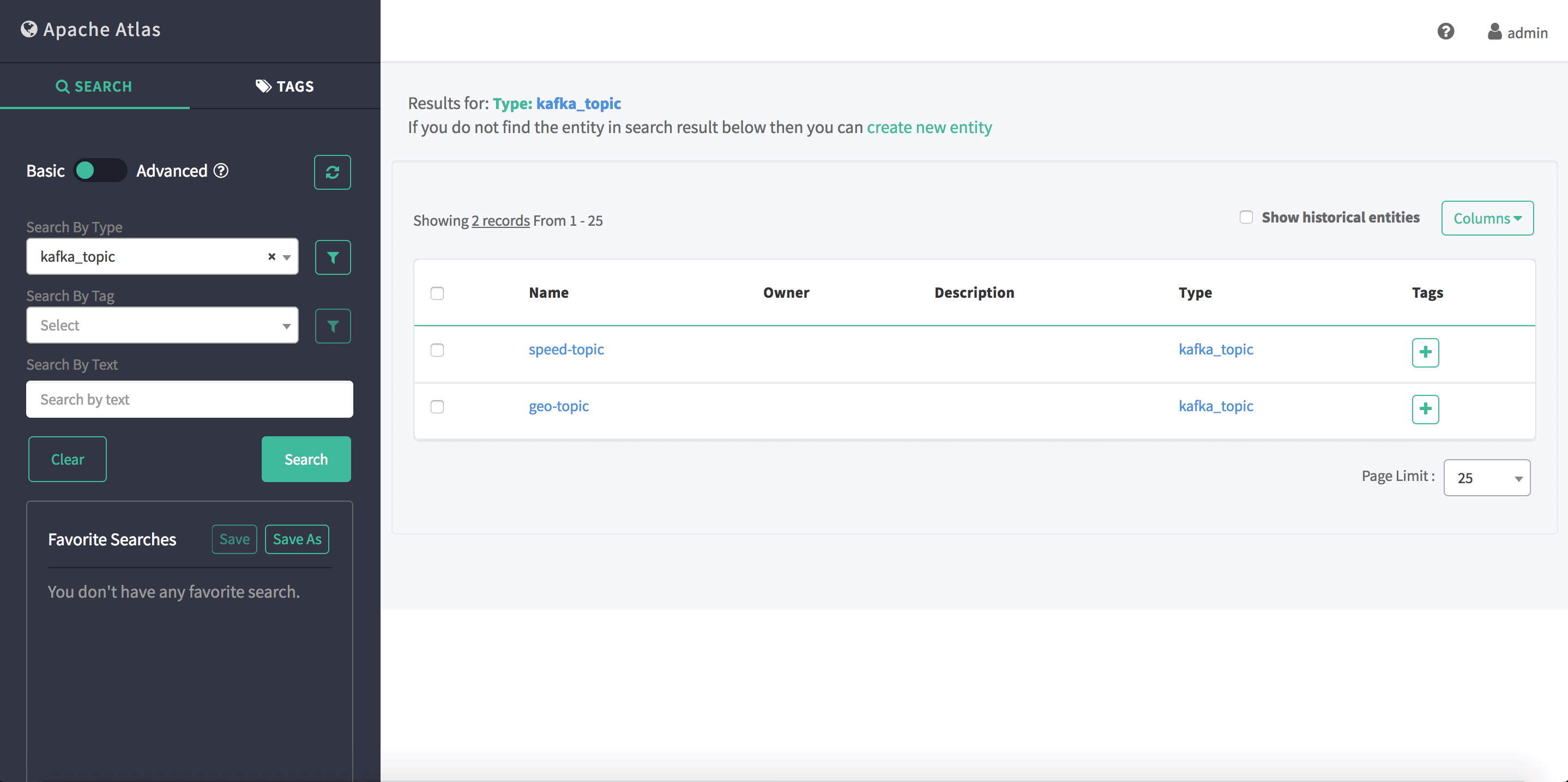
Fig.4: search results of kafka topics in Atlas
Now, when the lineage strategy is set to ‘simple path’, for a given kafka topic (geo-topic), we cannot identify which processor is contributing data, because both ‘GenerateFlowFile’ processors are connected to the same ‘PublishKafkaRecord’ processor. By only analyzing the flow definition file and each individual SEND event, we are missing the one-on-one mapping between NiFi processors and kafka topics. Therefore, the following Atlas lineage graph can be expected (Fig.5).
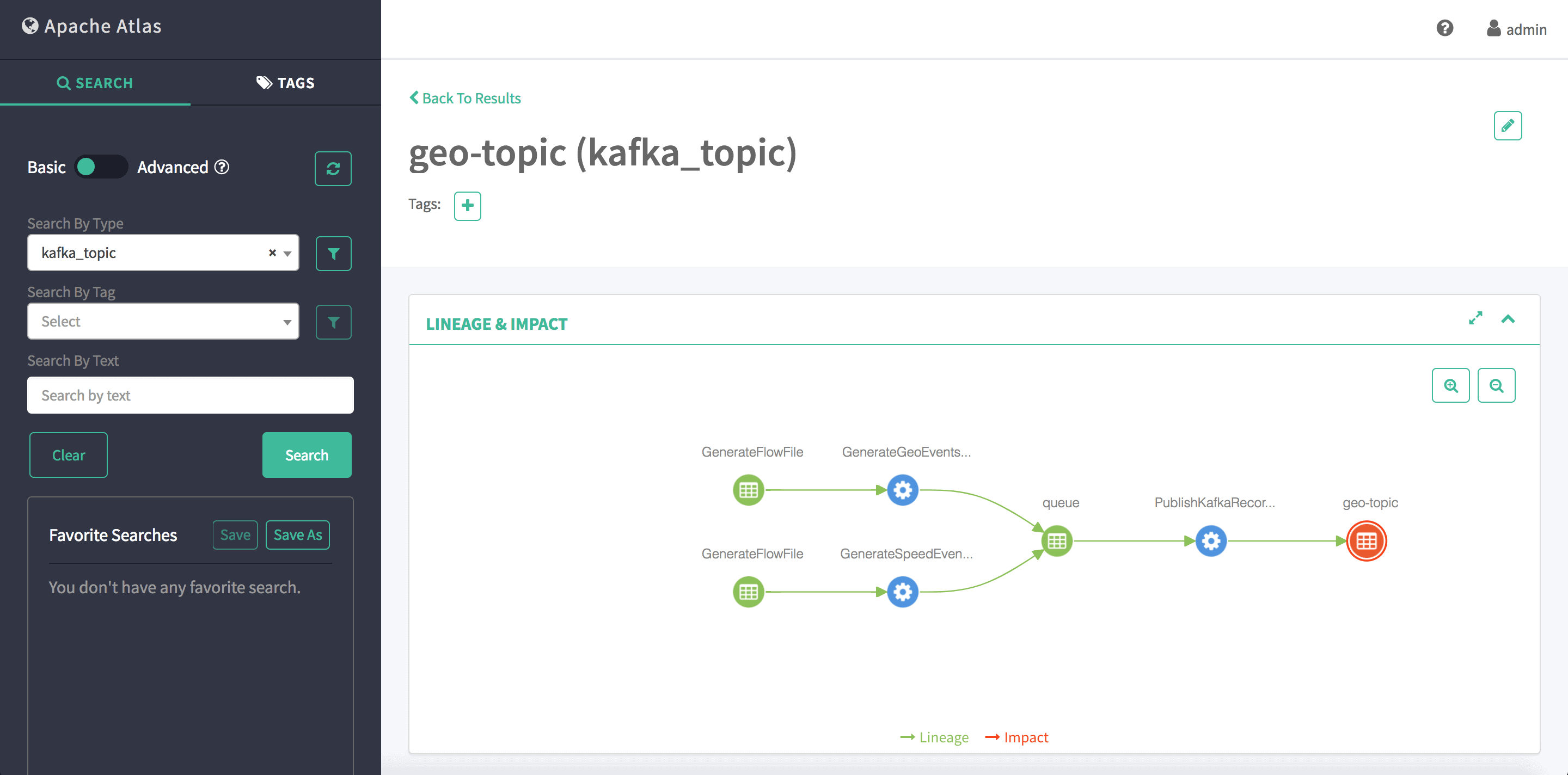
Fig.5: Atlas lineage graph (simple path strategy)
On the flip side, when the lineage strategy is set to ‘complete path’, we can clearly extract the one-on-one mapping by analyzing the full provenance trace on the NiFi side, and send the information to Atlas. Notice that, since ‘complete path’ requires analyzing the entire lineage of any given FlowFile from where data was born to where it was dropped, ‘complete path’ requires significantly more resources. See Fig.6 for the corresponding lineage graph.
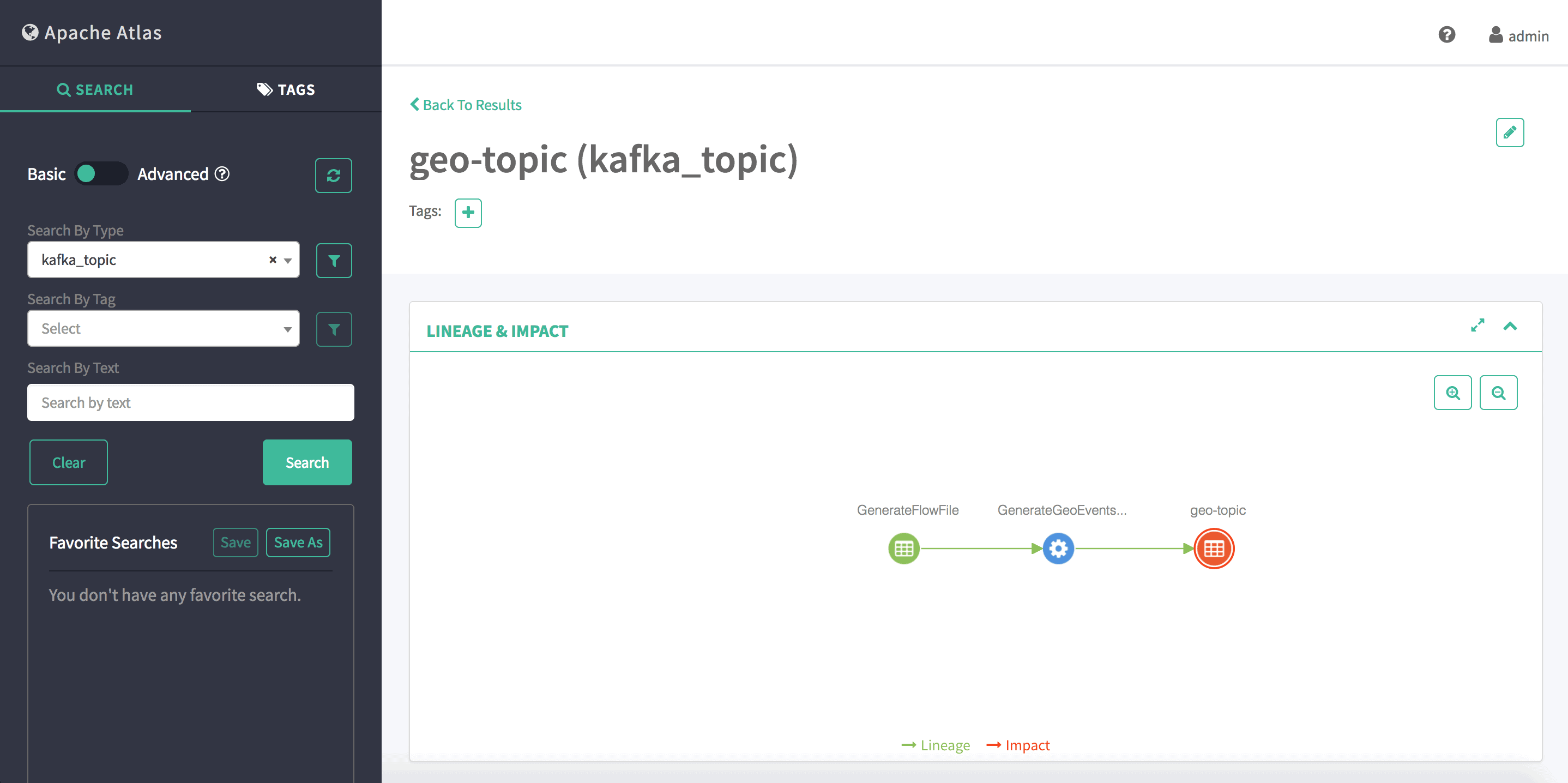
Fig.6: Atlas lineage graph (complete path strategy)
Supported Dataset Types
As part of the HDF 3.1 release, we support the following dataset types (and their qualified names) between NiFi and Atlas. More dataset types are definitely coming down the road.
Hive Database
qualifiedName=dbName@clusterName (example: default@cl1)
name=dbName (example: default)
Hive Table
qualifiedName=dbName.tableName@clusterName (example:default.testTable@cl1)
name=tableName (example: testTable)
Hive Column
qualifiedName=dbName.tableName.columnName@clusterName (example: default.testTable.lastName@cl1)
name=columnName (example: lastName)
Kafka topic
qualifiedName=topicName@clusterName (example: testTopic@cl1)
name=topicName (example: testTopic)
HDFS file
qualifiedName=/path/fileName@clusterName (example: /app/warehouse/hive/db/default@cl1)
name=/path/fileName (example: /app/warehouse/hive/db/default)
clusterName=clusterName (example: cl1)
HBase table
qualifiedName=tableName@clusterName (example: myTable@cl1)
name=tableName (example: myTable)
HBase column-family
qualifiedNmae=tableName.columnFamilyName@clusterName (example: myTable.cf1@cl1)
name=columnFamilyName (example: cf1)
HBase column
qualifiedName=tableName.colFamilyName.columnName@clusterName (example: myTable.cf1.col1@cl1)
name=columnName (example: col1)
What’s Next?
In the next installment of the HDF 3.1 Blog Series, we will discuss the powerful new extensibility in SAM: Building, Registering and using custom Kinesis Sources and S3 Sinks in SAM Streaming Analytics App. Stay tuned.
Interested in discussing further?
Join us for our HDF 3.1 webinar series where we dig deeper into the features with the Hortonworks product team. Redefining Data-in-Motion with Modern Data Architectures.
Editor's Choice


Hope we can still achieve this functionality,even if it is a NiFi publishing to Confluent kafka and Nifi integrated with Atlas. Key question is the Kafka topic would be still searchable from Atlas.