


This blog post was published on Hortonworks.com before the merger with Cloudera. Some links, resources, or references may no longer be accurate.
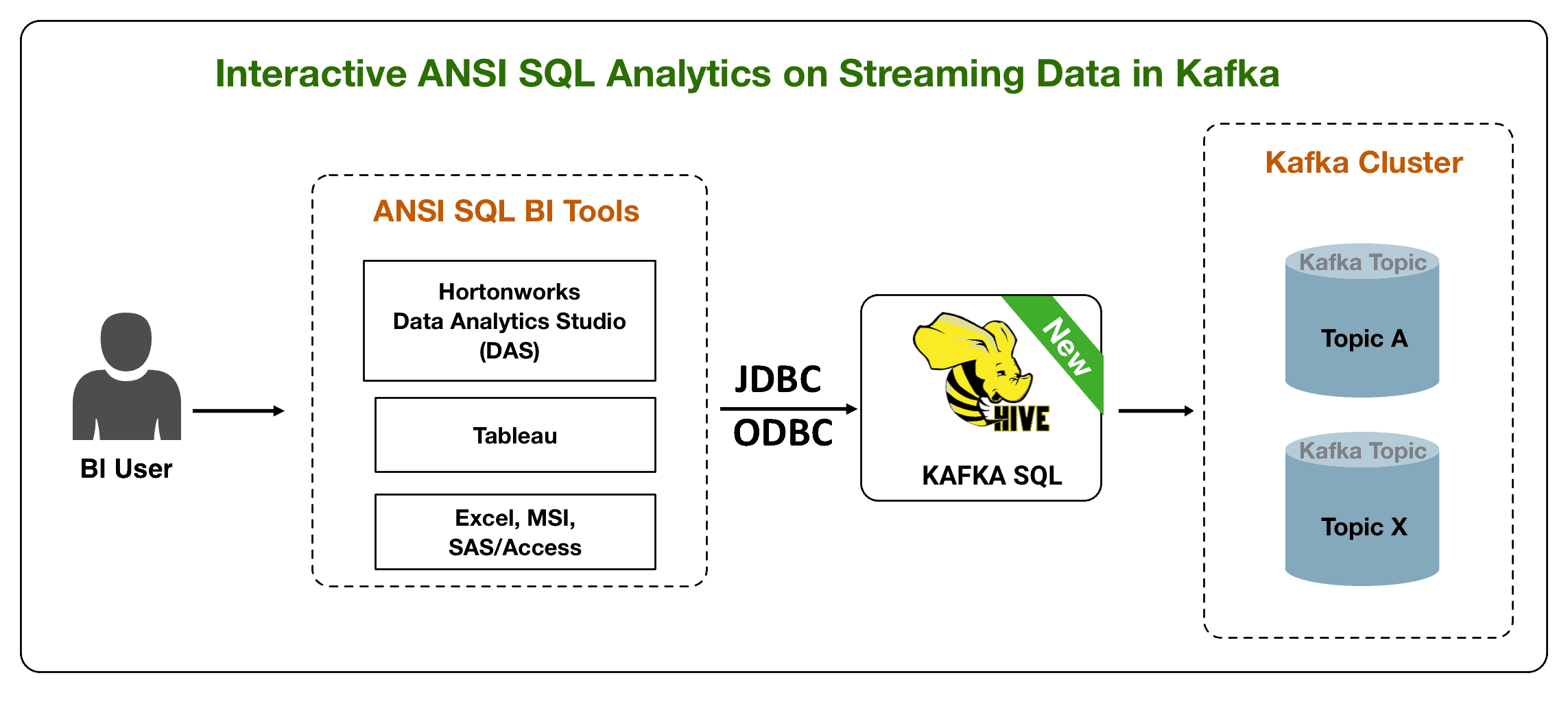
Our last few blogs as part of the Kafka Analytics blog series focused on the addition of Kafka Streams to HDP and HDF and how to build, secure, monitor Kafka Streams apps / microservices. In this blog, we focus on the SQL access pattern for Kafka with the new Kafka Hive Integration work.
Kafka SQL – What our Kafka customers have been asking for
Stream processing engines/libraries like Kafka Streams provide a programmatic stream processing access pattern to Kafka. Application developers love this access pattern but when you talk to BI developers, their analytics requirements are quite different which are focused on use cases around ad hoc analytics, data exploration and trend discovery. BI persona requirements for Kafka access include:
- Treat Kafka topics/streams as tables
- Support for ANSI SQL
- Support complex joins (different join keys, multi-way join, join predicate to non-table keys, non-equi joins, multiple joins in the same query)
- UDF support for extensibility
- JDBC/ODBC support
- Creating views for column masking
- Rich ACL support including column level security
To address these requirements, the new HDP 3.1 release has added a new Hive Storage Handler for Kafka which allows users to view Kafka topics as Hive tables. This new feature allows BI developers to take full advantage of Hive analytical operations/capabilities including complex joins, aggregations, window functions, UDFs, pushdown predicate filtering, windowing, etc.
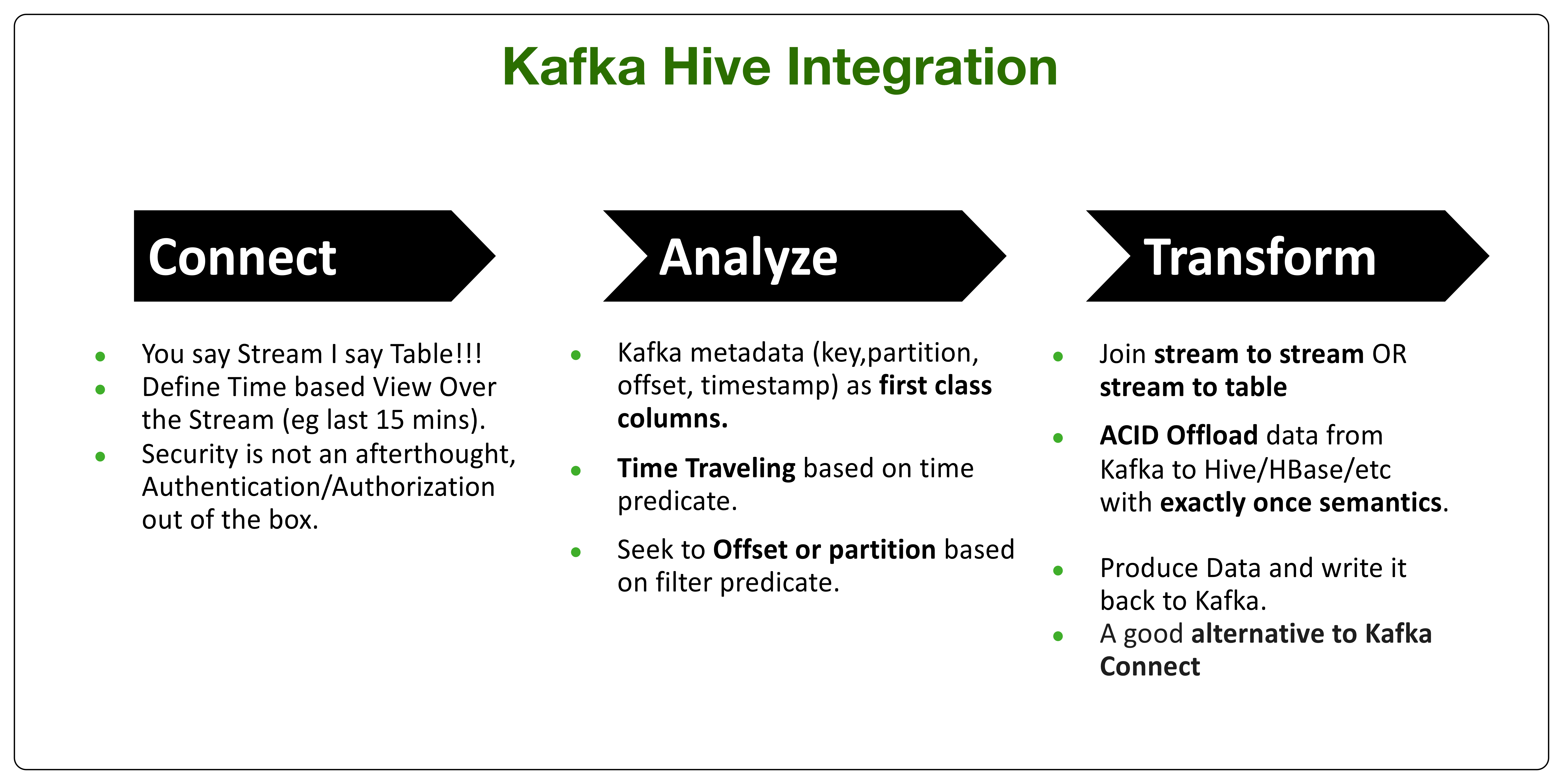
Kafka Hive C-A-T (Connect, Analyze, Transform)
The goal of the Hive-Kafka integration is to enable users the ability to connect, analyze and transform data in Kafka via SQL quickly.
- Connect: Users will be able to create an external table that maps to a Kafka topic without actually copying or materializing the data to HDFS or any other persistent storage. Using this table, users will be able to run any SQL statement with out of the box authentication and authorization support using Ranger.
- Analyze: Leverage Kafka time travel capabilities and offset based seeks in order to minimize I/O. Having such capabilities will enable both ad hoc queries across time slices in the stream and will allow exactly once offloading by controlling the position in the stream.
- Transform: Users will be able to masque, join, aggregate and change the serialization encoding of the original stream and create a stream persisted in a Kafka topic. Joins can be against any dimension table or any stream. User will be able to offload the data from Kafka to Hive warehouse (eg HDFS, S3 …etc).
The Connect of Kafka Hive C-A-T
To connect to a Kafka topic, execute a DDL to create an external Hive table representing a live view of the Kafka stream. The external table definition is handled by a storage handler implementation called ‘KafkaStorageHandler’. The storage handler relies on 2 mandatory table properties to map the Kafka topic name and the Kafka broker connection string. The below shows a sample DDL statement (more examples can be found here):
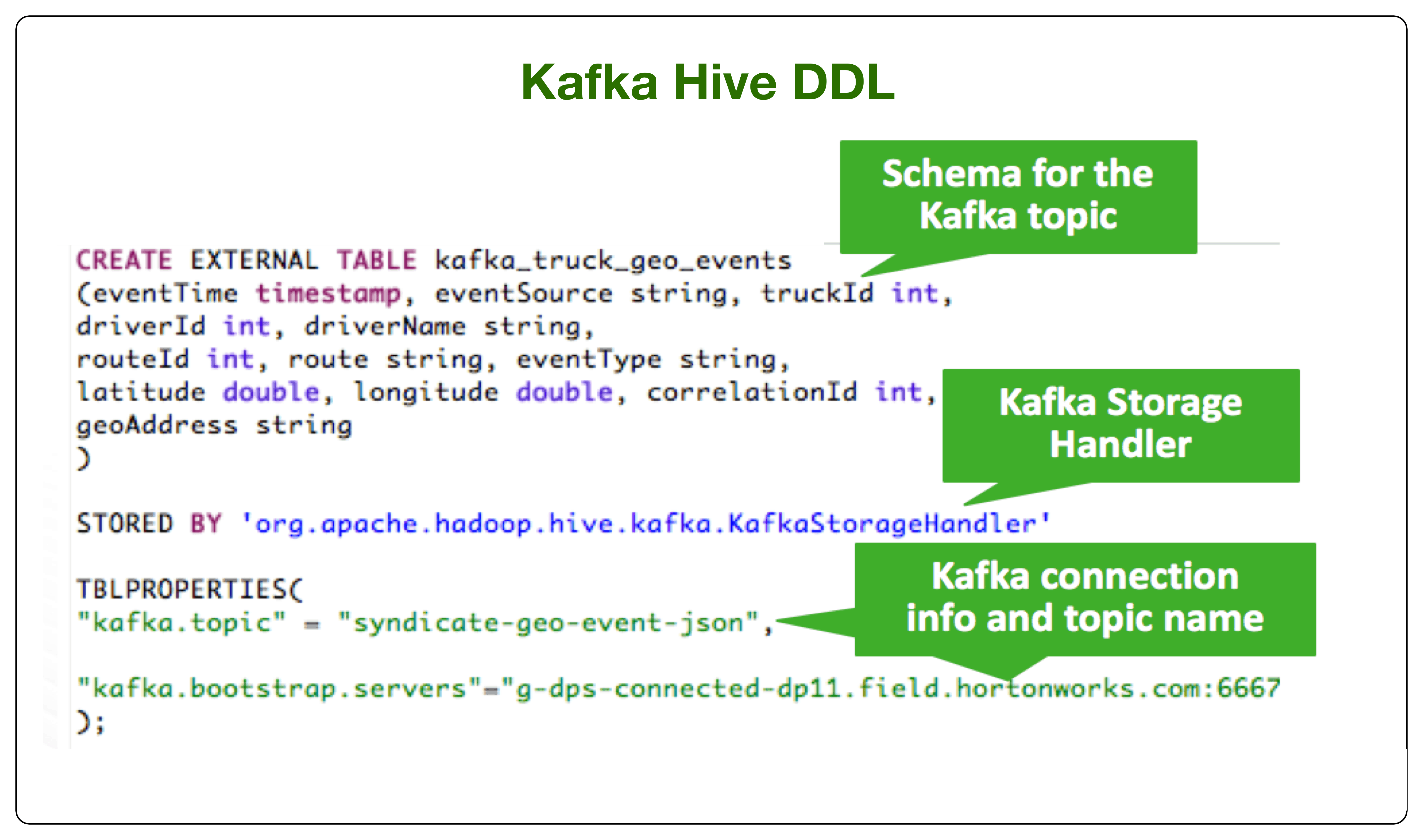
Recall that records in Kafka are stored as a key-value pairs, therefore the user needs to supply the serialization/deserialization classes to transform the value byte array into a set of columns. Serialization/Deserialization are supplied using the table property “kafka.serde.class”. As of today the default is JsonSerDe and there is out of the box serdes for formats such as csv, avro, and others.
In addition to the schema columns defined in the DDL, the storage handler captures metadata columns for the Kafka topic including partition, timestamp and offset. The metadata columns allows Hive to optimize queries for “time travel”, partition pruning and offset based seeks.

Time-Travel, Partition Pruning and Offset Based Seeks: Optimizations for Fast SQL in Kafka
From Kafka release 0.10.1 onwards, every Kafka message has a timestamp associated with it. The semantics of this timestamp is configurable (e.g: value assigned by producer, when leader receives the message, when a consumer receives the message, etc.). Hive adds this timestamp field as a column to the Kafka Hive table. With this column, users can use filter predicates to time travel (e.g: read only records past a given point in time). This is achieved using the Kafka consumer public API OffsetsForTime that returns the offset for each partitions earliest offset whose timestamp is greater than or equal to the given timestamp. Hive parses the filter expression tree and looks for any predicate in the the following form to provide time based offset optimizations: __timestamp [>= , >, =] constant_int64. This will allow optimization for queries like:

Customers leverage this powerful optimization by creating time based views of the streaming data into Kafka like the following (e.g: a view over the last 15 minutes of the streaming data into Kafka topic kafka_truck_geo_events). The implementation of this optimization can be found here: KafkaScanTrimmer#buildScanForTimesPredicate

Partition pruning is another powerful optimization. Each Kafka Hive table is partitioned based on the __partition metadata column. Any filter predicate over column __partition can be used to eliminate the unused partitions. See optimization implementation here: KafkaScanTrimmer#buildScanFromPartitionPredicate
Kafka Hive also takes advantages of offset based seeks which allows users to seek to specific offset in the stream. Thus any predicate that can be used as a start point eg __offset > constant_64int can be used to seek in the stream. Supported operators are =, >, >=, <, <=.
See optimization implementation here: KafkaScanTrimmer#buildScanFromOffsetPredicate
Implementing Discovery/Trend Analytics Requirements with Kafka Hive Integration
Let’s bring this full circle with a concrete example of using Kafka Hive SQL to implement a series of requirements on streaming data into Kafka.

The below video showcases how to implement each of these requirements.
Whats Next?
In the next installment of the Kafka Analytics Blog series, we will cover the Kafka Druid Integration for fast OLAP style analytics on streaming data into Kafka.
Editor's Choice


Where does the data in the table kafka_truck_geo_events come from? I have no idea after reading this for 3 times
It is coming for kakfa topic, which was mentioned while creating table.
Good job, but i have a question. How long the record can present on hive table?