

This blog post was published on Hortonworks.com before the merger with Cloudera. Some links, resources, or references may no longer be accurate.
IN HDF 3.1, we announced support for Apache Kafka 1.0 with powerful integrations with Apache Ambari, Apache Ranger, and Apache Atlas. In the last 12 months, we have seen Kafka emerge as a key component in many of our customers streaming architectures’. A common architecture looks something like the following:

Different customers or even different groups within the same organization have different approaches to do analytics on the stream but Kafka is constant, it’s everywhere, and is a key component in many of our customers’ architectures.
Kafka Blindness
Over the last 12 months, the product team has been talking to our largest Kafka customers who are using this technology to implement a diverse set of use cases. We posed to them the following question:
What are your key challenges with using Kafka in production? What do you need to be successful with this powerful technology?
The most common response was the need for better tools to monitor and manage Kafka in production. Specifically, users wanted better visibility in understanding what is going on in the cluster across the four key entities with Kafka: producers, topics, brokers, and consumers. In fact, because we heard this same response over and over from the users we interviewed, we gave it a name: The Kafka Blindness.
Kafka’s Omnipresence has led to Kafka blindness – the enterprise’s struggle to monitor, troubleshoot and see whats happening in their Kafka clusters.
Who is Affected? What are their Symptoms?
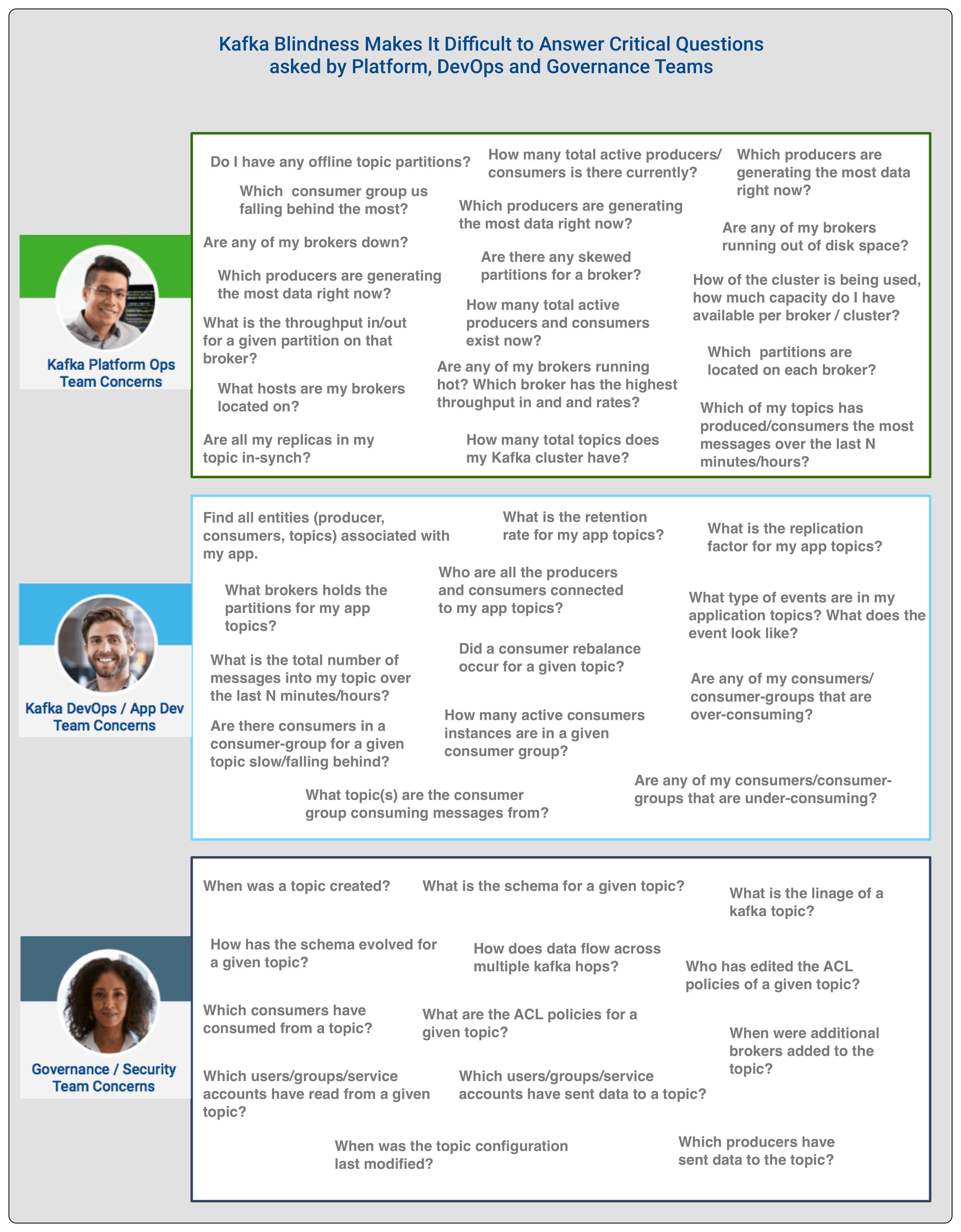
The symptoms of the Kafka blindness affliction varied based on the teams we talked to. For a platform operations team, it was the lack of visibility at a cluster and broker level and the effects of the broker on the infrastructure it runs on and vice versa. While for a DevOps/App team, the user is primary interested in the entities associated with their applications. These entities are the topics, producers and consumers associated with their application. The DevOps/App Dev team wants to know how data flows between such entities and understand the key performance metrics (KPMs) of these entities. For governance and security teams, the questions revolve around chain of custody, audit, metadata, access control and lineage.
The below image represents the different questions that three groups have difficulty answering because of Kafka Blindness…
Current Tools to Treat Kafka Blindness are Ineffective
- No tools available!
- Kafka CLI utilities located in the kafka/bin directory.
- A couple of open source tools with limited functionality
- Homegrown solutions/scripts that analyze JMX metrics and internal Kafka topics to query key metrics.
- Proprietary solutions that do not have a broader platform and that cause vendor lock-in.
Based on the interviews, there was an overwhelming consensus that these tools were ineffective treatments for the following key reasons:
- No centralized dashboard, single pane of glass, that was able to answer the common questions asked by Operations/Platform and DevOps/App dev teams.
- No ability to see how data moved across the four entities in Kafka: Producers, Brokers, Topics, and Consumers
- No ability to know whether something is going wrong within Kafka until a failure happens
- No ability to know whether someone incorrectly configured any aspect of Kafka
- Missing first class support for REST services to integrate with other monitoring tools
- Lack of support for secure/kerberized clusters
A Cure for Kafka Blindness is Coming…
Over the last 12 months, the product team has conducted over 30+ interviews with subject matter experts at our largest Kafka customers across Telco, Healthcare, Insurance and Transportation to understand how to cure this illness. We have collected a corpus of data points and based on this, the engineering team has been diligently building a new tool to assist platform operations, devops/app dev and security/governance teams to answer the questions above.
Over the next few weeks, we plan to open source this innovation. In an upcoming blog, we will provide more details. Stay Tuned. But for now, to spark your interest, here is a glimpse…
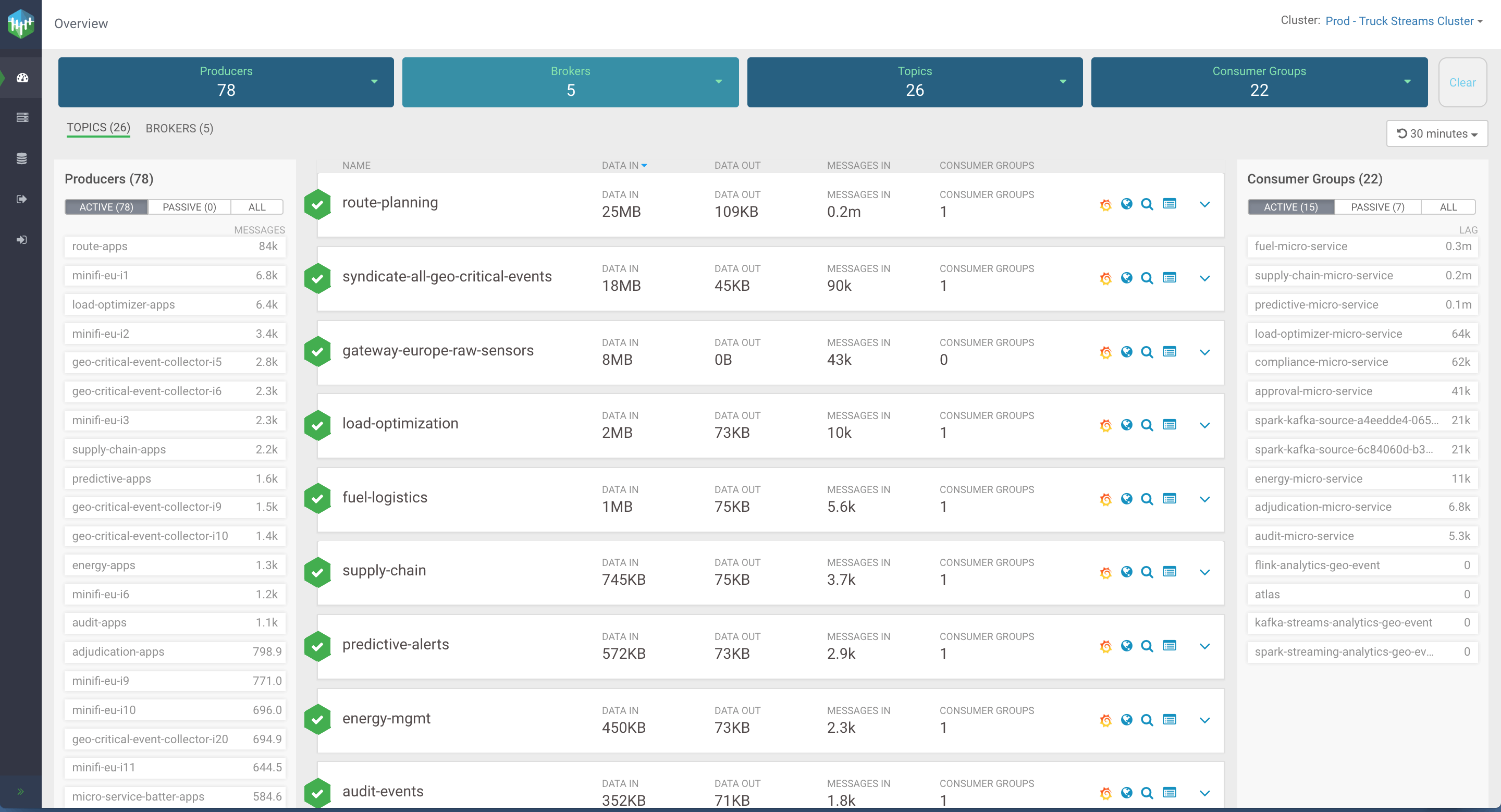
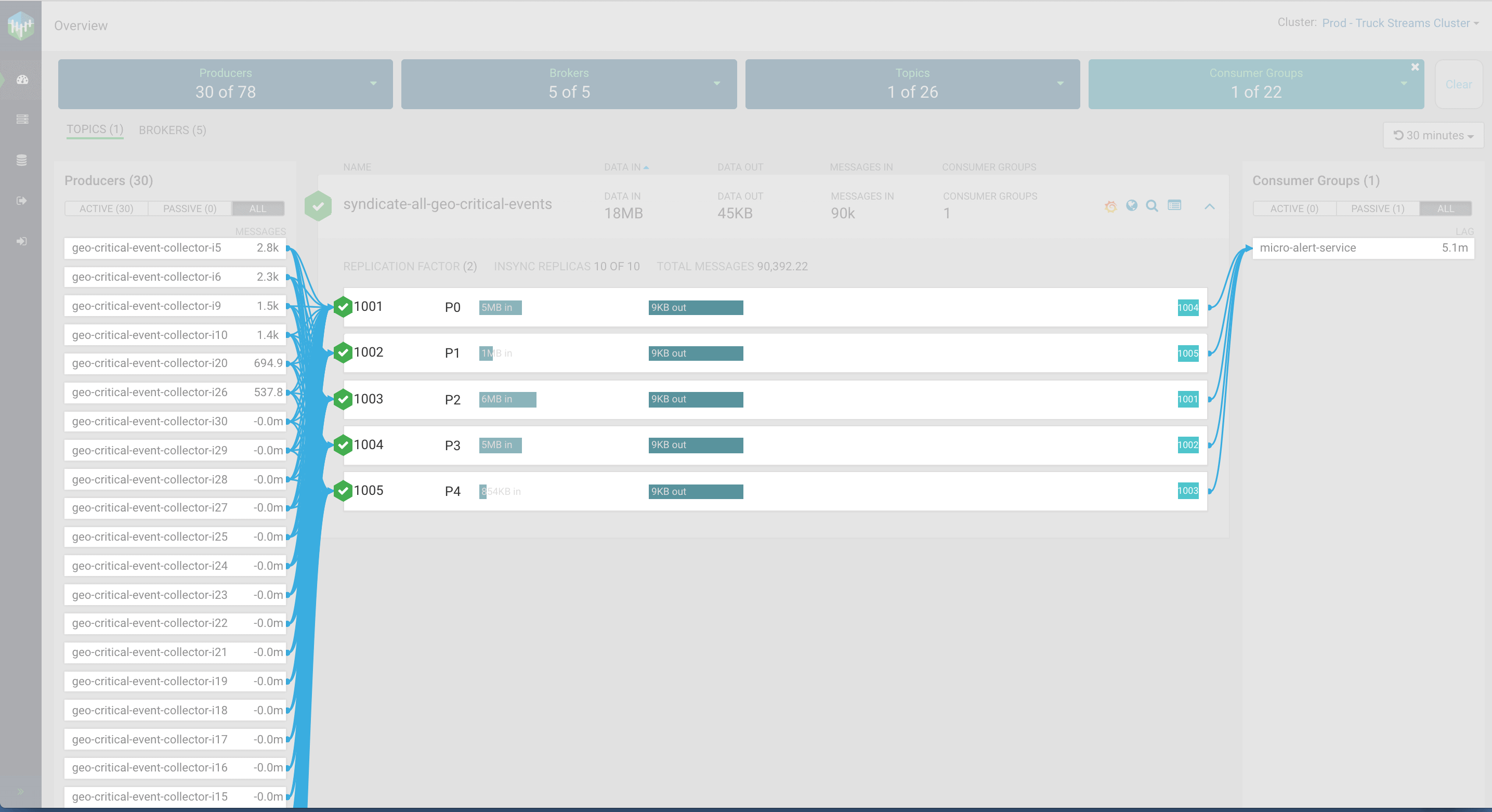
Editor's Choice

