

This blog post was published on Hortonworks.com before the merger with Cloudera. Some links, resources, or references may no longer be accurate.
In an earlier blog post, Democratizing Analytics within Kafka With 3 Powerful New Access Patterns in HDP and HDF, we discussed different access patterns that provides application developers and BI analysts powerful new tools to implement diverse use cases where Kafka is key component of their application architectures. In this blog, we will discuss in detail the streaming access pattern and the addition of Kafka Streams support in HDF 3.3 and the upcoming HDP 3.1 release.
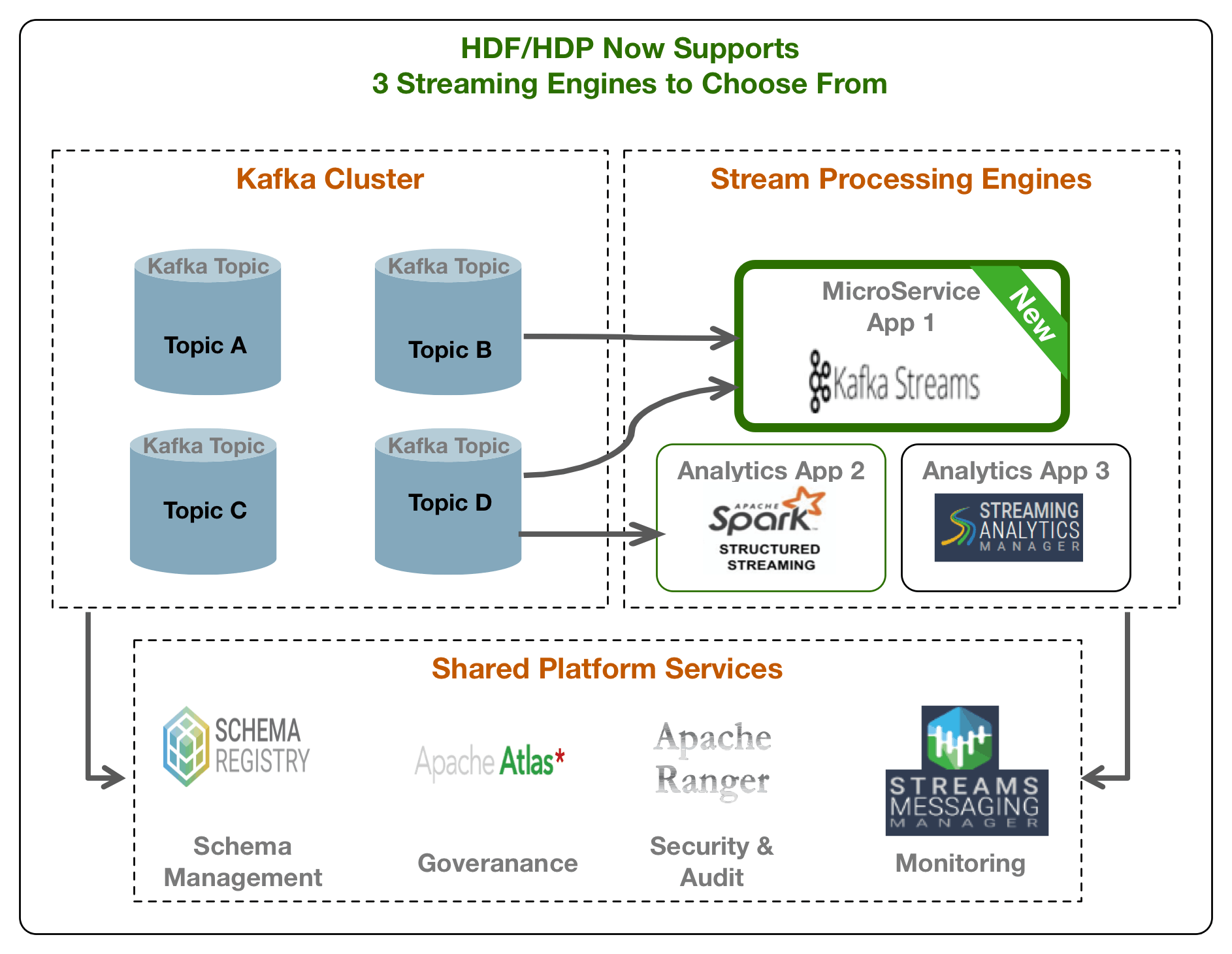
Before the addition of Kafka Streams support, HDP and HDF supported two stream processing engines: Spark Structured Streaming and Streaming Analytics Manager (SAM) with Storm. So naturally, this begets the following question:
Why add a third stream processing engine to the platform?
With the choice of using Spark structured streaming or SAM with Storm support, customers had the choice to pick the right stream processing engine based on their non- functional requirements and use cases. However, neither of these engines addressed the following types of requirements that we saw from our customers:
- Lightweight library to build eventing-based microservices with Kafka as the messaging/event backbone.
- The application runtime shouldn’t require a cluster.
- Cater to application developers who want to programmatically build streaming applications with simple APIs for less complex use cases.
- Requirements around exactly-once semantics where the data pipelines only consist of Kafka.
Kafka Streams addresses each of these requirements. With the addition of Kafka Streams, customers now have more options to pick the right stream processing engine for their requirements and use cases. The below table provides some general guidelines / comparisons.
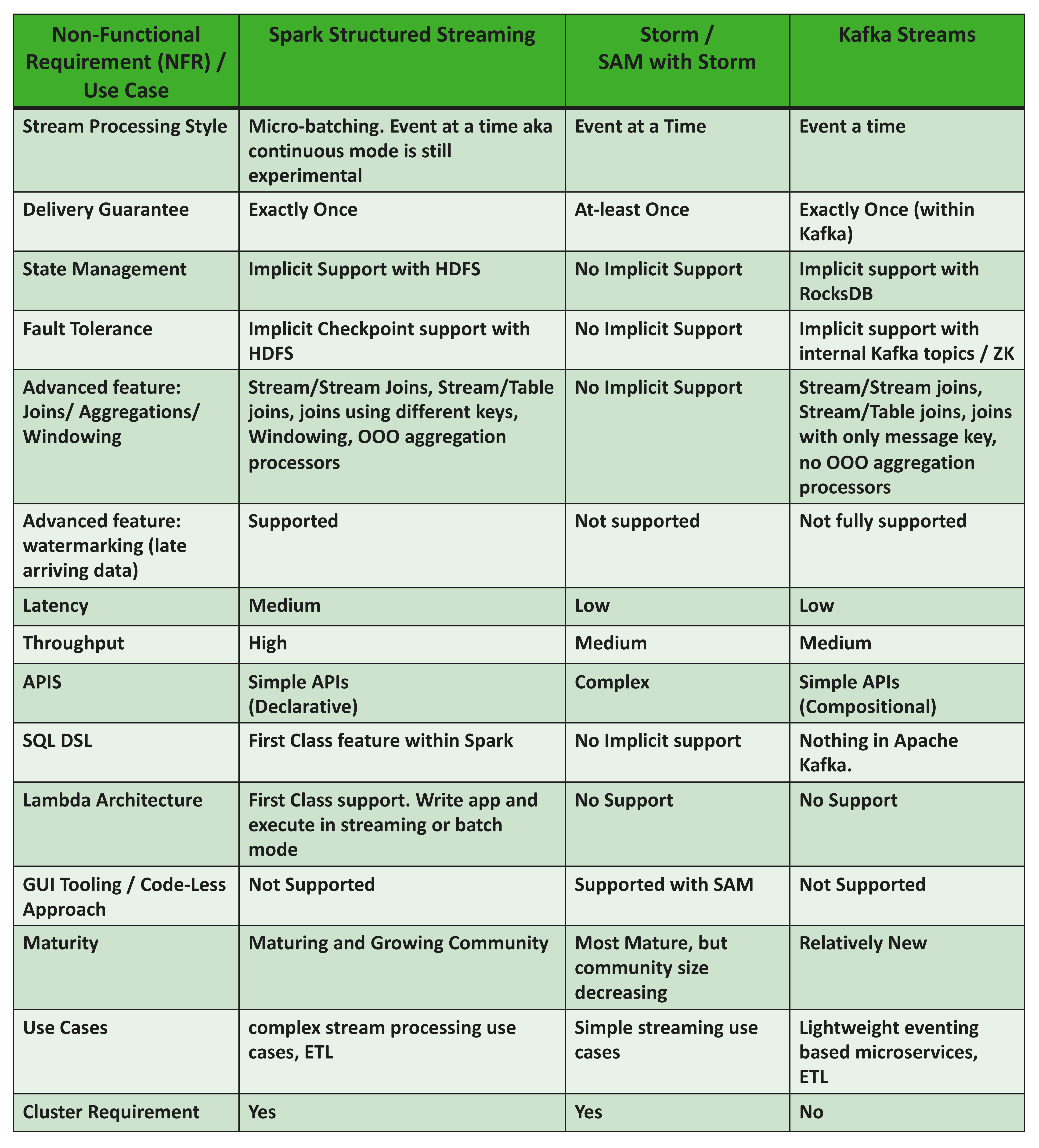
The table above is packed with lots of information. So, when is Kafka Streams an ideal choice for your stream processing needs? Consider the following:
- Your stream processing application consists of Kafka to Kafka pipelines.
- You don’t need/want another cluster for stream processing.
- You want to perform common stream processing functions like filtering, joins, aggregations, enrichments on the stream for simpler stream processing apps.
- Your target users are developers with java dev backgrounds.
- Your use cases are about building lightweight microservices, simple ETL and stream analytics apps.
Each of these three supported streaming engines use a centralized set of platform services providing security (authentication / authorization), audit, governance, schema management and monitoring capabilities.
What’s Next
In the following post to this, we will demonstrate using Kafka Streams integrated with Schema Registry, Atlas and Ranger to build set of microservices apps using a fictitious use case.
Editor's Choice

