

On September 22nd at 10:00 am PST, Vincent Lam, Director of Product Marketing at Protegrity, and Syed Mahmood, Sr. Product Marketing Manager at Hortonworks, will be talking about how to secure sensitive data in Hadoop Data Lakes.
In this blog, they provide answers to some of the most frequently asked questions they have heard on the topic.
- What’s the best approach for the security of Hadoop Data Lakes?
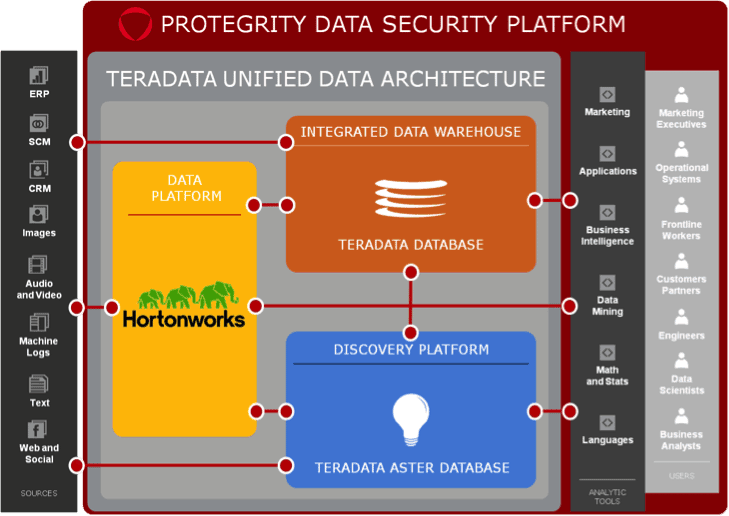
As enterprises continue to harness the power of Hadoop to store large amounts of data, security becomes an even more important part of the ecosystem. While it’s never too late to implement security, it’s best to make security part of any Hadoop project as a requirement from the beginning. This provides the best opportunities for implementing security best practices and addressing governance requirements. Effective Hadoop security depends on a holistic approach. Hortonworks framework for comprehensive security revolves around five pillars: administration, authentication/ perimeter security, authorization, audit and data protection. Security administrators provide enterprise-grade coverage across each of these pillars as they design the infrastructure to secure data in Hadoop.
Hortonworks helps customers maintain the high levels of protection their enterprise data demands by building centralized security administration and management into the DNA of the Hortonworks Data Platform (HDP). The HDP ecosystem leverages partnerships like Protegrity’s Avatar and Big Data Protector to offer additional data security in the form of fine grained protection to complement Hortonworks native capabilities.
- What is the difference between coarse-grained and fine-grained protection?
Coarse-grained and fine-grained protection of data refers to how the data security is applied. For instance, HDFS can provide coarse-grained protection by encrypting all data written to disk. This can provide data loss prevention if the disk is physically stolen or if disk data is copied. However, this level of protection is an all or nothing approach. Since all the data is readable to users of the system, how do you protect the data itself?
Fine-grained protection of data refers to the protection of the actual data elements. By actually changing the values of the data written into Hadoop, the data is protected even if it is moved or tentatively read by an unauthorized user. This protection is selective and can be defined for particular sensitive data elements. For example, Protegrity can tokenize or encrypt social security numbers and dates of birth in place while leaving other data intact. This provides the most comprehensive protection possible by protecting sensitive data elements at rest, in use, and in transit.
- How does tokenization protect data?
Tokenization secures a data value by replacing the data value with a completely unrelated value of the same kind and format. So for instance, if a date of birth of the form MM/DD/YYYY is tokenized, the token is also of the form MM/DD/YYYY. Since there is no relationship between the original value and the arbitrary token, this technique is very secure. In fact, if you’ve swiped your credit card recently, the information was tokenized during the transaction process. Traditional tokenization methods rely on large tables to map between tokens and data elements. Fortunately, methods like Protegrity vaultless tokenization, allow for high performance in Hadoop environments by eliminating these tables and leveraging nodes.
From a usability perspective, since tokenized data is of the same kind and format as the original data, applications don’t need to be recoded to utilize the data. Policies can dictate how different users and roles will see sensitive data. Some users may see data in the clear while others may only portions of the data or no data at all. This allows for partitions of users to analyze data in aggregate correctly without identifying the underlying record itself – permitting maximum benefit of data lake analysis without the risk.
- What does a workflow for Hadoop protection look like?
The overall workflow for Hadoop secures data before it enters the lake, enables applications to leverage the data, and detokenizes (if applicable) the data at the point of consumption. Before data enters the Hadoop data lake, it is protected at ingestion with a protector. This protector tokenizes or encrypts sensitive data elements whether it comes from a file, application, database, or other source. Any sensitive data that enters Hadoop is protected. When the data needs to be consumed or analyzed, UDFs and APIs provide detokenization capabilities to the consumer. Based on the role of the user, the data will be presented differently based on their privileges. The Hadoop ecosystem, including Pig, Hive, Sqoop, and MapReduce, is completely supported. All this takes place transparently to end users and ensures protection throughout the lifecycle of data within the data lake and beyond.
Editor's Choice

