

This blog post was published on Hortonworks.com before the merger with Cloudera. Some links, resources, or references may no longer be accurate.
This is the second in a series of data science blogs that we plan to publish. The first blog outlined the data science and data engineering capabilities of Hortonworks Data Platform. In this blog we highlight how the latest release of Apache Hive 3 can work with Apache Spark
Motivation
As enterprises embrace the value proposition of Big Data to create their next generation data architecture, they are targeting a variety of use cases for that platform. These include traditional scenarios likes BI analytics and ETL processing along with newer applications like predictive analytics and machine learning. And for all of these scenarios, enterprises expect efficient and fast processing that’s best in class, as well as consistent security and governance across all use cases. Based on our experience, it’s apparent that there is no one processing framework that solves all scenarios and meets the target expectations. This is because excelling in each scenario requires strong domain focus and sustained investments over a period of time. Frameworks like Apache Hive are focused on BI analytics with innovations in transactions, cost based optimizers improvements etc. For complex processing and machine learning, Apache Spark is adding high-performance integration with Python, R and TensorFlow.
Hence, it’s increasingly becoming clear that single framework platforms may not be able to provide a complete solution that addresses all functional scenarios. Choosing multiple frameworks from different vendors creates potential friction, security and governance risks as users, credentials and data flow across vendor boundaries. With HDP, we endeavor to making this easy for customers by providing the best in class frameworks on the same platform, with seamless interoperability and consistent security and governance across the frameworks.
To make things concrete, consider the common scenario of an end to end data pipeline. We first need to perform some complex ETL of raw data into a relational system. We can use Apache Spark’s deep language integration with Scala/Python to do that easily and ingest the data into an Apache Hive warehouse using transactional ingest support to provide data freshness. Hive is then used to provide fast access to that fresh data, via LLAP, to power dashboards and other business tools with fine grained access control. Next, the same access control should be applied when Apache Spark jobs read data from that Hive warehouse in order to train machine learning models on that data. We can see how multiple best in class frameworks need to inter-operate seamlessly and with consistent security and governance, in order to meet the desired business objectives.
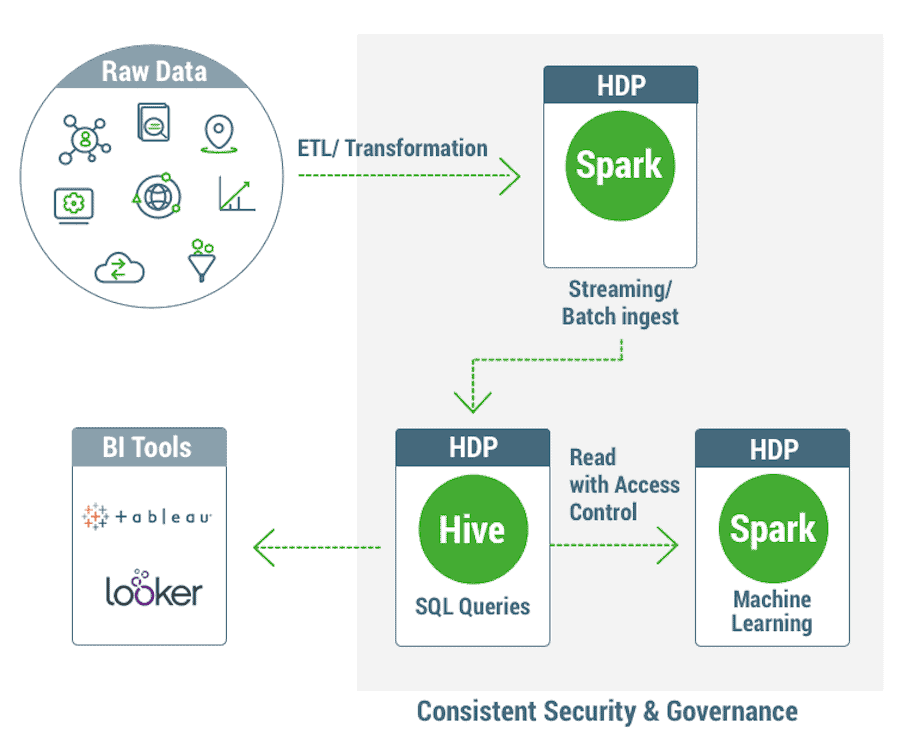
Apache Spark and Hive Integration
The latest release of Apache Hive 3 (part of HDP 3) provides significant new capabilities including ACID support for data ingest. This functionality has many applications, a crucial one being privacy support for data modifications and deletions for GDPR. In addition, ACID also significantly reduces the time to ingest for data, thereby improving data freshness for Hive queries. To provide these features, Hive needs to take full control of the files that store the table data and thus this data is no longer directly accessible by third party systems like Apache Spark. Thus Apache Spark’s built-in support for Hive table data is no longer supported for data managed by Hive 3.
At the same time, Apache Spark has become the de-facto standard for a wide variety complex processing use cases on Big Data. This includes data stored in Hive 3 tables and thus we need a way to provide efficient, high-performance, ACID compliant access to Hive 3 table data from Spark. Fortunately, Apache Spark supports a pluggable approach for various data sources and Apache Hive itself can also be considered as one data source. We have implemented the Hive Warehouse Connector (HWC) as library to provide first class support for Spark to read Hive 3 data for subsequent complex processing (like machine learning) in Spark.
Spark is also commonly used to ETL raw data into Hive tables and this scenario should continue to be supported in the Hive ACID world. To do that, HWC integrates with the latest Hive Streaming APIs to support ingest into Hive both from batch jobs as well as structured streaming jobs.
Overall the Hive Warehouse connector provide efficient read write access to Hive warehouse data from Spark jobs, while providing transparent user identity propagation and maintaining consistent security and access control.
User Scenarios
Batch Reads
The architecture for batch reads is powered by LLAP daemons serving as a trusted intermediary to read Hive 3 data from disk. This allows LLAP to reconcile ACID transactions in the data and also to apply Ranger based fine grained policies like columns masking on the data before handing it to Spark. LLAP supports Apache Arrow based data serialization format to efficiently transfer data to Spark executors, leveraging Apache Spark existing native support for Arrow data. HWC tries to leverage Hive features, including filter pushdown, predicate pruning etc., to ensure an optimal read of data from Hive into Spark. The net benefit for end users is efficient access to Hive data from Spark while maintaining fine grained access control policies to that data.
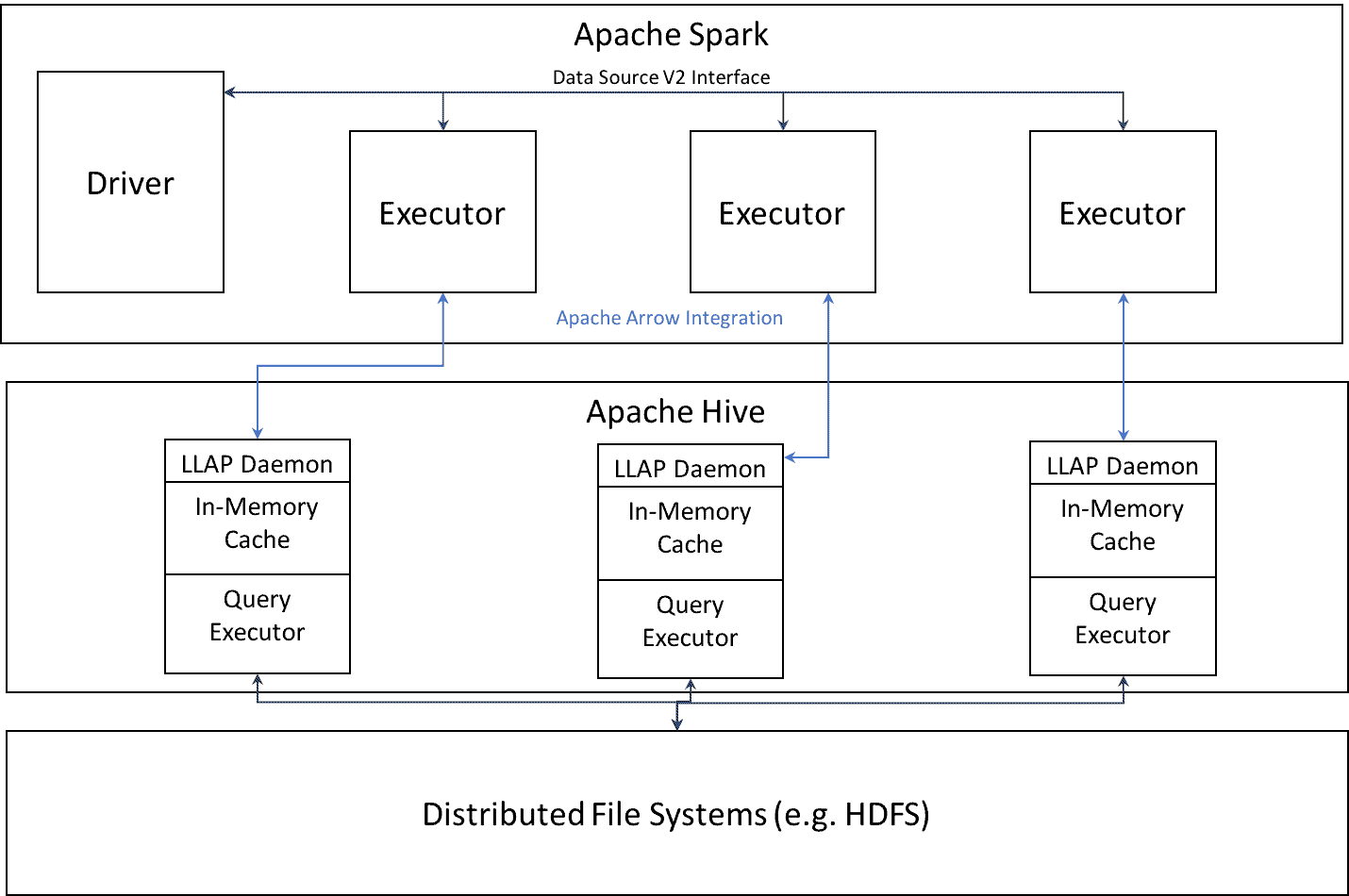
Batch Writes
Hive Warehouse Connector integrates with Hive APIs to allow direct ingest of batch data into the Hive ACID warehouse. This enables existing ETL pipelines to continue to work after they change their code to use the HWX API. In addition to the standard constructs supported via the Spark data source API, HWC may also provide advanced functionality like merge, upsert etc. via new APIs exposed by HWC.
Streaming Writes
Hive Warehouse Connector also integrates with the structured streaming functionality in Spark. Now users can perform continuous ETL using Spark structured streaming jobs directly into Hive 3 ACID tables. This features provide at-least once semantics for the streaming application with plans to enable exactly-once semantics in the future.
For more details on how to set this up and start using it, including code samples, please refer to the HCC article here. The code for the Hive Warehouse Connector is open source and available here.
Editor's Choice

