

The Why
In the previous blog, we talked about the Open Hybrid Architecture. This architecture decouples storage and computation, thus computation tasks need to access various types of storage systems. This requires the ability to mount an external storage volume onto a container so that the container can read/write data just like on a local file system. It will be complex if we provide an implementation for each and every storage system. Thus the motivation of adopting Container Storage Interface (CSI) is to easily integrate with arbitrary storage systems through a unified interface. Apache Hadoop Ozone is a new Object Store for Apache Hadoop, and it provides compatibility with AWS S3 protocol via s3-gateway. As a result, by using an existing 3rd party csi-s3 plugin, it becomes possible to attach Ozone volumes to YARN containers via CSI.
What is CSI ?
Container Storage Interface is a vendor neural interface that aims to bridge container orchestrators and storage systems. It defines three gRPC service protocols: identity, controller and node. A storage system only needs to provide a driver which implements these services in order to provide the ability to expose its storage volume to a container orchestrator system. CSI is one of the projects at the Cloud Native Computing Foundation (CNCF), the first version was published in February 2018, and the latest version is 1.0 which is published in November 2018.
Container Storage Interface – Bridge Container Orchestrator and Storage Systems
By leveraging CSI, YARN only needs to talk with CSI drivers, through CSI public APIs. The vendor-specific code will only stay in the driver itself. In this blog, we will introduce how we support attaching Apache Ozone volumes with CSI in YARN.
Architecture
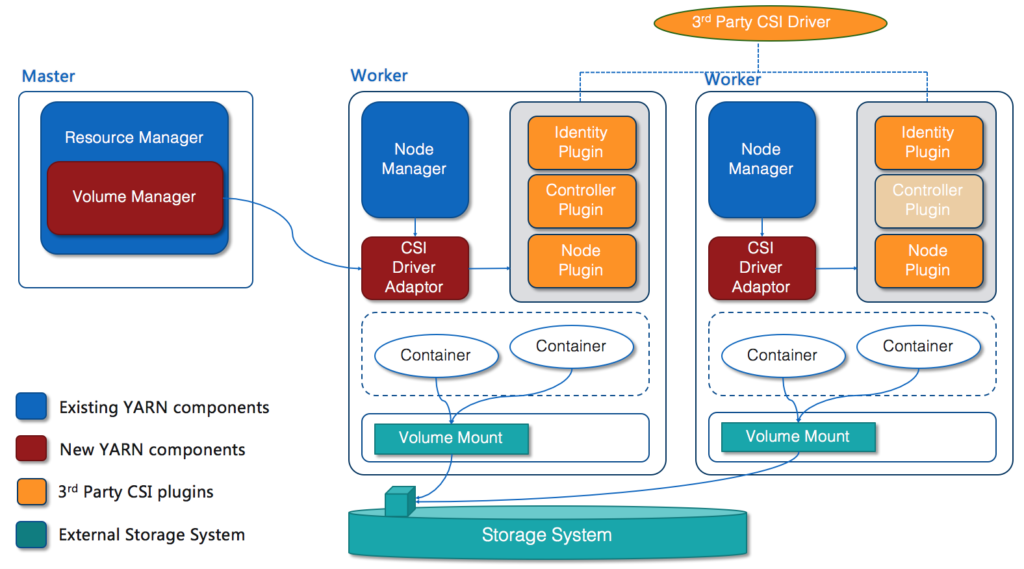
In order to work with external storage systems, the csi-driver for such systems must be deployed on each node manager. Each node will run an instance of identity / node service, and one node in the cluster will run an instance of controller service. What’s more, several new components are added to negotiate with csi-driver upon volume requests, see the following chart:
The Adaption of Container Storage Interface in YARN – Architecture
The new components are:
| Component | Description |
| CSI Driver | A csi-driver is a set of CSI gRPC services (identity/controller/node), it runs on each NodeManager and listens on a unix domain socket address. The driver implements all the required APIs to manage storage volume’s lifecycle. The driver is provided by the storage system. |
| Volume Manager | Volume manager reads the csi-volume spec and handles volume operations by connecting to the controller service on a csi-driver. This module manages the lifecycle of CSI volumes in YARN. Volume manager runs inside of ResourceManager process. |
| CSI Driver Adaptor | The CSI driver adaptor runs on all node managers, side by side with csi-driver. It proxies all invocations between YARN and CSI driver. The adaptor also needs to register itself to the volume manager and one of them will be the primary talking to the controller plugin. |
The design and implementation of this feature are available in JIRA YARN-8811.
Volume Lifecycle
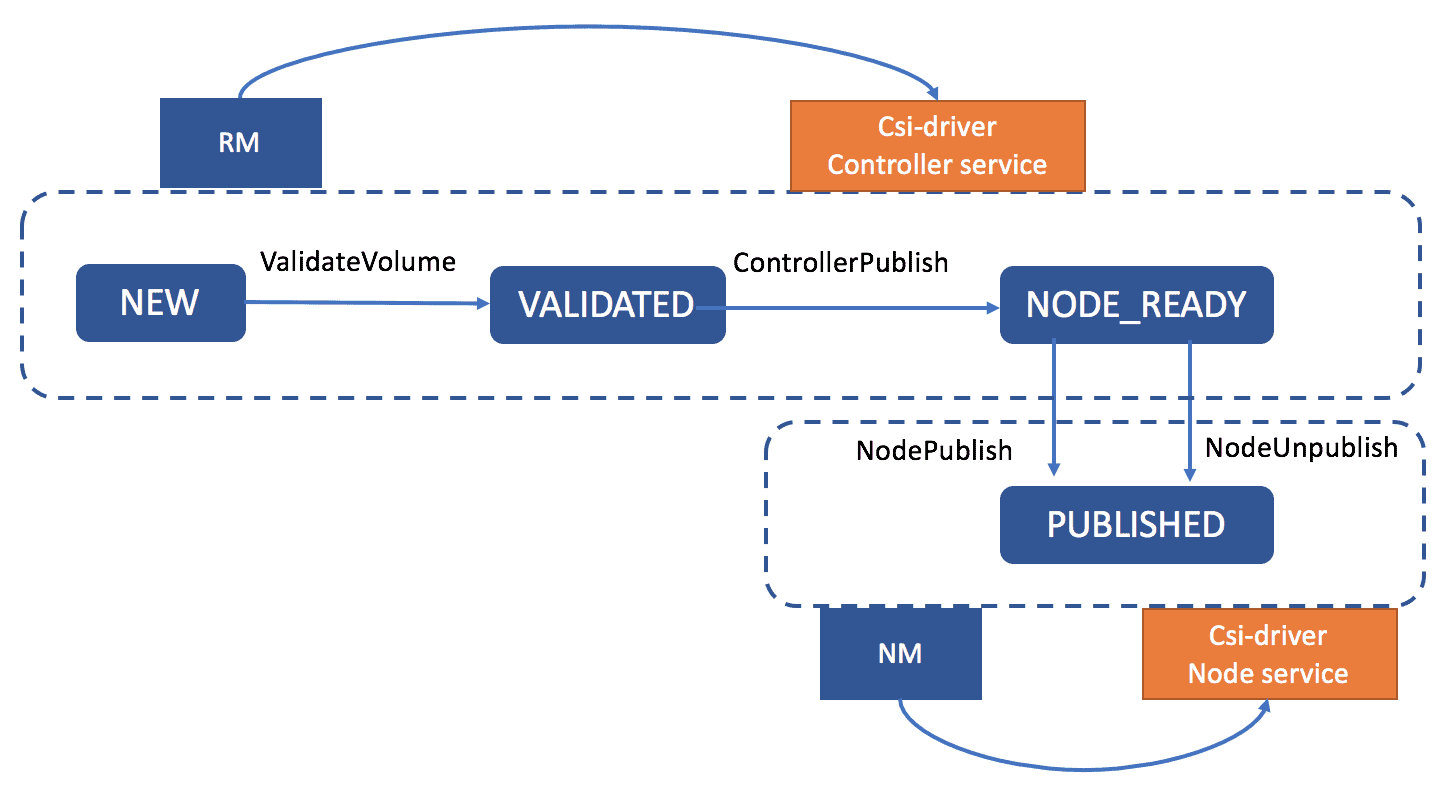
At the time of writing, work has completed in YARN only to support pre-provisioned volumes. This means the volumes must be created by a user before it can be used in YARN. To attach such volumes in YARN containers, volume lifecycle transits like below,
Pre-provisioned Volume Lifecycle Management
On the resource manager host, the volume reaches NODE_READY state and on the node manager host, it finally reaches PUBLISHED state. Then it can be accessed by docker containers. Dynamically provisioned volume, on the other hand, has a more complex life cycle, for instance, creation and destruction of a volume is also needed.
Hello-world: A Stateful App with Persisted Data in Apache Ozone
1) Configure CSI drivers
Apache Ozone has a compatible S3 gateway interface from version 0.3.0-alpha. With the work in YARN-8811, YARN is now capable of mounting external storage volumes using CSI standard. By leveraging S3 Gateway in Ozone, YARN could mount S3 volumes by using standard S3 CSI drivers, and containers could now read/write data to Ozone directly.
This demo leverages a 3rd party CSI S3 driver from https://github.com/CTrox/csi-s3. Goofys is a high-performance, POSIX-ish Amazon S3 file system which is used by this csi-s3 driver to mount storage volumes as per CSI standard.
Quick Steps:
1.1 Install goofys in the host machine by using simple go command like this
go install github.com/kahing/goofys
1.2 Clone and compile csi-s3 driver from https://github.com/CTrox/csi-s3.git
1.3 Run s3 driver as below by providing Ozone S3 endpoint as http://ozone_s3_host:9878
sudo ./_output/s3driver -nodeid 1 -endpoint unix://tmp/csi.sock -s3-endpoint http://ozone_s3_host:9878 -mounter goofys -secret-access-key qwe -access-key-id qwe
2) Populate data in an Ozone volume
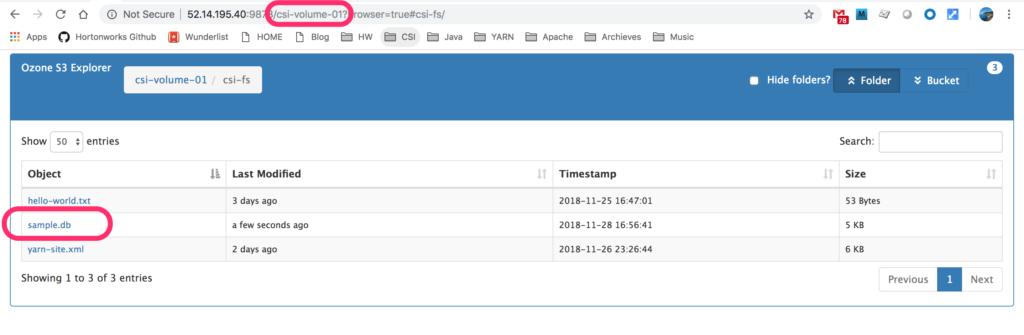
Create a volume in Ozone and copy a sample database file to the volume. From Ozone browser, make sure the data is uploaded successfully. Sample.db is a simple SQLite DB file used for demonstration purpose.
Volumes in Ozone Browser
3) Write a YARN service specification
Volumes are considered a special type of resource, which can be done by extending the existing resource model. For example, following resource specification defines a resource request which asks for 1 vcore, 1024MB memory and 1GB volume from an external Apache Ozone storage system (bridging by a csi-s3-driver).
// truncated from a service spec file
"resource": {
"cpus": 1,
"memory": "1024",
"additional": {
"yarn.io/csi-volume": {
"value": 1,
"unit": "Gi",
"attributes" : {
"volume.id" : "csi-volume-01",
"driver.name" : "ch.ctrox.csi.s3-driver",
"volume.mount" : "/mnt/data",
"access.mode": "SINGLE_NODE_WRITTER",
"read.only" : "false"
}
}
}
}
4) Launch service job
yarn app -launch sample-csi-service service.json
5) Review the application
A containerized web application loads data from Ozone volume
This simple PHP page loads the data from /mnt/data/sample.db, and this file exists on the Ozone volume. The volume is mounted to the mount point /mnt/data in this container by YARN.
Demo Video
Here is a short recorded video illustrating the example used in this blog ↓
Summary
This blog introduces why and how YARN adoptes CSI as a general solution to attach external storage volumes to containerized workloads. This adds the ability to build stateful apps on top of YARN. At the time of writing, only pre-provisioned volume is supported. The future work includes support of dynamical provisioned volumes, user credentials and integrates with more storage systems.
YARN-8811 is the umbrella JIRA to track this feature. Thanks to Vinod Kumar Vavilapalli, Wangda Tan, Eric Yang, Saumitra Buragohain, Shane Kumpf, Rohith Sharma KS, Anu Engineer, Marton Elek, Zhankun Tang for contributing ideas.
Editor's Choice

