

The latest version of Hortonworks Data Platform (HDP) introduced a number of significant enhancements for our customers. For instance, HDP 2.6.0 now supports both Apache Spark™ 2.1 and Apache Hive™ 2.1 (LLAP™) as GA. Often customers store their data in Hive and analyze that data using both Hive and SparkSQL. An important requirement in this scenario is to apply the same fine-grained access control policy to Hive data, irrespective of whether the data is analyzed using Hive or SparkSQL. This fine-grained access control includes features such as row/ column level access or data masking. With HDP 2.6.0, row/ column level security in Spark SQL 2.1 is in technical preview which is scheduled to GA in the upcoming HDP 2.6.1 release.
Security has always been a fundamental requirement for enterprise adoption. For example, in a company, billing, data science, and regional marketing teams may all have the required access privileges to view customer data, while sensitive data like credit card numbers should be accessible only to the finance team. Previously, Apache Hive™ with Apache Ranger™ policies was used to manage such scenarios. Now, in HDP 2.6, Apache Spark SQL is aware of the existing Apache Ranger™ policies defined for Apache Hive.
Key Benefits of SparkSQL with HDP 2.6
- Shared Access Control Policies: The data in a cluster can be shared securely, and can be consistently controlled by the common access control rules between SparkSQL and Hive.
- Audits: All access via SparkSQL can be monitored and searched through a centralized interface that is Ranger.
- Resource Management: Each user can use a unique queue while accessing the securely shared data.
- Minimum Transition Cost: Since this feature offers row/ column level security in SQL, existing Spark 2.1 apps and scripts and all Spark shells (spark-shell, pyspark, sparkR, spark-sql) are supported without any modifications.
With row/ column level security, different SQL users may see different results for the same queries, based on the applied policy. In other words, users only see the data based on their identity per Kerberos principal. Access to databases, tables, rows and columns are controlled in a fine-grained manner.
SparkSQL Access Patterns
There are various access patterns for Spark SQL – Spark Thrift Server over JDBC/ODBC, Spark shells, and Spark applications. SparkSQL can also be accessed over Spark Thrift Server via Apache Zeppelin’s JDBC interpreter. HDP 2.6 supports all these access patterns.
Example Data and Ranger Access Control Policy
Let’s imagine that we have a customer table, `t_customer`, in a database `db_spark` that contains the following data.
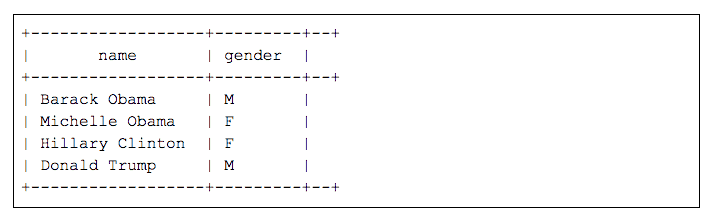
There are two users, `datascience` and `billing`. The access control policy defined in Apache Ranger limits the `datascience` user access to only male customers and gives access to only the first four characters of their names. The `billing` user doesn’t have this restriction.
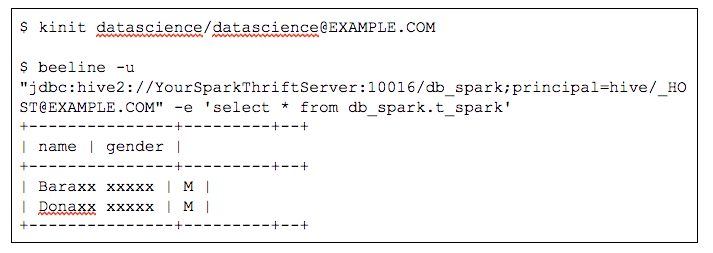
SQL access to Hive tables over JDBC/ODBC via Spark Thrift Server
In the example below, `datascience` user is logged into both `beeline` and `Zeppelin` and can only access male users and the last name of the user is masked.
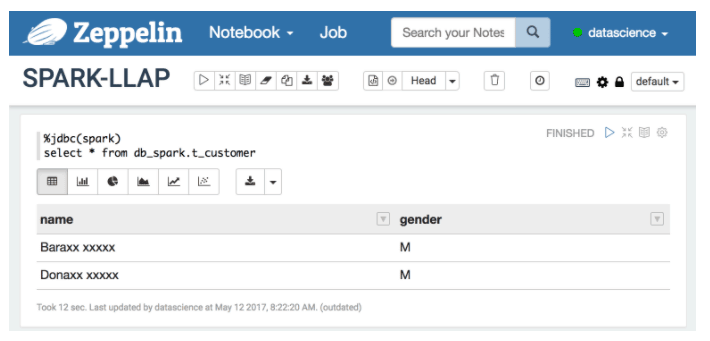
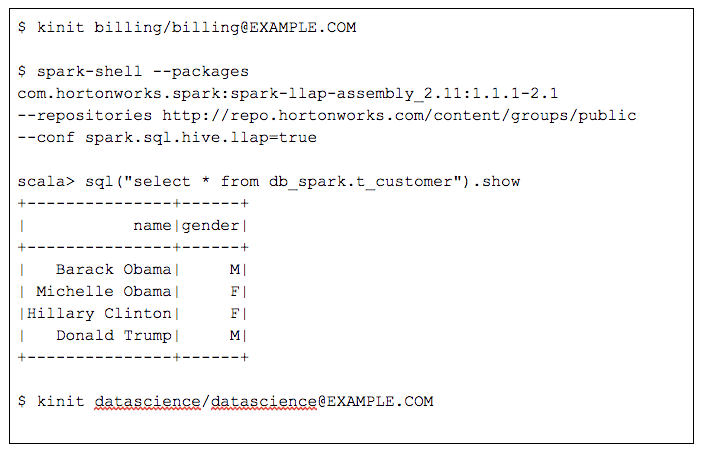
Programmatic Access to Hive Tables Using Scala/ Python/ R
When both users run the same SQL query to retrieve all the data from the customer table, the results are different. The following session shows two spark-shell commands, one for the ‘billing’ user and the other for the more restricted ‘datascience’ user.

Conclusion
Access control is a key enterprise requirement and now SparkSQL offers enterprise-grade fine-grained access control with row/ column level access, masking, and redaction. Now access via SparkSQL follows the same access control policy that Hive users follow. This removes a key limitation of SparkSQL and we think will have more adoption of SparkSQL.
A demo of this feature can be viewed in this youtube video:
To try out this feature in your HDP 2.6 environment, refer to this HCC article which provides detailed instructions.
We look forward to your feedback and want to thank our customers & Apache Spark, Apache Ranger, and Apache Hive communities for their input and help.
Editor's Choice

