

This blog post was published on Hortonworks.com before the merger with Cloudera. Some links, resources, or references may no longer be accurate.
We are proud to announce the technical preview of Spark-HBase Connector, developed by Hortonworks working with Bloomberg.
The Spark-HBase connector leverages Data Source API (SPARK-3247) introduced in Spark-1.2.0. It bridges the gap between the simple HBase Key Value store and complex relational SQL queries and enables users to perform complex data analytics on top of HBase using Spark. An HBase DataFrame is a standard Spark DataFrame, and is able to interact with any other data sources such as Hive, ORC, Parquet, JSON, etc.
Background
There are several open source Spark HBase connectors available either as Spark packages, as independent projects or in HBase trunk.
Spark has moved to the Dataset/DataFrame APIs, which provides built-in query plan optimization. Now, end users prefer to use DataFrames/Datasets based interface.
The HBase connector in the HBase trunk has a rich support at the RDD level, e.g. BulkPut, etc, but its DataFrame support is not as rich. HBase trunk connector relies on the standard HadoopRDD with HBase built-in TableInputFormat has some performance limitations. In addition, BulkGet performed in the the driver may be a single point of failure.
There are some other alternative implementations. Take Spark-SQL-on-HBase as an example. It applies very advanced custom optimization techniques by embedding its own query optimization plan inside the standard Spark Catalyst engine, ships the RDD to HBase and performs complicated tasks, such as partial aggregation, inside the HBase coprocessor. This approach is able to achieve high performance, but it difficult to maintain due to its complexity and the rapid evolution of Spark. Also allowing arbitrary code to run inside a coprocessor may pose security risks.
The Spark-on-HBase Connector (SHC) has been developed to overcome these potential bottlenecks and weaknesses. It implements the standard Spark Datasource API, and leverages the Spark Catalyst engine for query optimization. In parallel, the RDD is constructed from scratch instead of using TableInputFormat in order to achieve high performance. With this customized RDD, all critical techniques can be applied and fully implemented, such as partition pruning, column pruning, predicate pushdown and data locality. The design makes the maintenance very easy, while achieving a good tradeoff between performance and simplicity.
Architecture
We assume Spark and HBase are deployed in the same cluster, and Spark executors are co-located with region servers, as illustrated in the figure below.
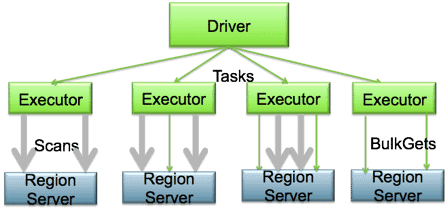
Figure 1. Spark-on-HBase Connector Architecture
At a high-level, the connector treats both Scan and Get in a similar way, and both actions are performed in the executors. The driver processes the query, aggregates scans/gets based on the region’s metadata, and generates tasks per region. The tasks are sent to the preferred executors co-located with the region server, and are performed in parallel in the executors to achieve better data locality and concurrency. If a region does not hold the data required, that region server is not assigned any task. A task may consist of multiple Scans and BulkGets, and the data requests by a task is retrieved from only one region server, and this region server will also be the locality preference for the task. Note that the driver is not involved in the real job execution except for scheduling tasks. This avoids the driver being the bottleneck.
Table Catalog
To bring the HBase table as a relational table into Spark, we define a mapping between HBase and Spark tables, called Table Catalog. There are two critical parts of this catalog. One is the rowkey definition and the other is the mapping between table column in Spark and the column family and column qualifier in HBase. Please refer to the Usage section for details.
Native Avro support
The connector supports the Avro format natively, as it is a very common practice to persist structured data into HBase as a byte array. User can persist the Avro record into HBase directly. Internally, the Avro schema is converted to a native Spark Catalyst data type automatically. Note that both key-value parts in an HBase table can be defined in Avro format. Please refer to the examples/test cases in the repo for exact usage.
Predicate Pushdown
The connector only retrieves required columns from region server to reduce network overhead and avoid redundant processing in Spark Catalyst engine. Existing standard HBase filters are used to perform predicate push-down without leveraging the coprocessor capability. Because HBase is not aware of the data type except for byte array, and the order inconsistency between Java primitive types and byte array, we have to preprocess the filter condition before setting the filter in the Scan operation to avoid any data loss. Inside the region server, records not matching the query condition are filtered out.
Partition Pruning
By extracting the row key from the predicates, we split the Scan/BulkGet into multiple non-overlapping ranges, only the region servers that has the requested data will perform Scan/BulkGet. Currently, the partition pruning is performed on the first dimension of the row keys. For example, if a row key is “key1:key2:key3”, the partition pruning will be based on “key1” only. Note that the WHERE conditions need to be defined carefully. Otherwise, the partition pruning may not take effect. For example, WHERE rowkey1 > “abc” OR column = “xyz” (where rowkey1 is the first dimension of the rowkey, and column is a regular hbase column) will result in a full scan, as we have to cover all the ranges because of the OR logic.
Data Locality
When a Spark executor is co-located with HBase region servers, data locality is achieved by identifying the region server location, and makes best effort to co-locate the task with the region server. Each executor performs Scan/BulkGet on the part of the data co-located on the same host.
Scan and BulkGet
These two operators are exposed to users by specifying WHERE CLAUSE, e.g., WHERE column > x and column < y for scan and WHERE column = x for get. The operations are performed in the executors, and the driver only constructs these operations. Internally they are converted to scan and/or get, and Iterator[Row] is returned to catalyst engine for upper layer processing.
Usage
The following illustrates the basic procedure on how to use the connector. For more details and advanced use case, such as Avro and composite key support, please refer to the examples in the repository.
1) Define the catalog for the schema mapping:
[code language="scala"]def catalog = s"""{
|"table":{"namespace":"default", "name":"table1"},
|"rowkey":"key",
|"columns":{
|"col0":{"cf":"rowkey", "col":"key", "type":"string"},
|"col1":{"cf":"cf1", "col":"col1", "type":"boolean"},
|"col2":{"cf":"cf2", "col":"col2", "type":"double"},
|"col3":{"cf":"cf3", "col":"col3", "type":"float"},
|"col4":{"cf":"cf4", "col":"col4", "type":"int"},
|"col5":{"cf":"cf5", "col":"col5", "type":"bigint"},
|"col6":{"cf":"cf6", "col":"col6", "type":"smallint"},
|"col7":{"cf":"cf7", "col":"col7", "type":"string"},
|"col8":{"cf":"cf8", "col":"col8", "type":"tinyint"}
|}
|}""".stripMargin
[/code]
2) Prepare the data and populate the HBase table:
case class HBaseRecord(col0: String, col1: Boolean,col2: Double, col3: Float,col4: Int, col5: Long, col6: Short, col7: String, col8: Byte)
object HBaseRecord {def apply(i: Int, t: String): HBaseRecord = { val s = s”””row${“%03d”.format(i)}””” HBaseRecord(s, i % 2 == 0, i.toDouble, i.toFloat, i, i.toLong, i.toShort, s”String$i: $t”, i.toByte) }}
val data = (0 to 255).map { i => HBaseRecord(i, “extra”)}
sc.parallelize(data).toDF.write.options(
Map(HBaseTableCatalog.tableCatalog -> catalog, HBaseTableCatalog.newTable -> “5”))
.format(“org.apache.spark.sql.execution.datasources.hbase”)
.save()
3) Load the DataFrame:
def withCatalog(cat: String): DataFrame = {
sqlContext
.read
.options(Map(HBaseTableCatalog.tableCatalog->cat))
.format(“org.apache.spark.sql.execution.datasources.hbase”)
.load()
}
val df = withCatalog(catalog)
4) Language integrated query:
val s = df.filter((($”col0″ <= “row050″ && $”col0” > “row040”) ||
$”col0″ === “row005” ||
$”col0″ === “row020” ||
$”col0″ === “r20” ||
$”col0″ <= “row005”) &&
($”col4″ === 1 ||
$”col4″ === 42))
.select(“col0”, “col1”, “col4”)
s.show
5) SQL query:
df.registerTempTable(“table”)
sqlContext.sql(“select count(col1) from table”).show
Configuring Spark-Package
Users can use the Spark-on-HBase connector as a standard Spark package. To include the package in your Spark application use:
spark-shell, pyspark, or spark-submit
> $SPARK_HOME/bin/spark-shell –packages zhzhan:shc:0.0.11-1.6.1-s_2.10
Users can include the package as the dependency in your SBT file as well. The format is the spark-package-name:version
spDependencies += “zhzhan/shc:0.0.11-1.6.1-s_2.10”
Running in Secure Cluster
For running in a Kerberos enabled cluster, the user has to include HBase related jars into the classpath as the HBase token retrieval and renewal is done by Spark, and is independent of the connector. In other words, the user needs to initiate the environment in the normal way, either through kinit or by providing principal/keytab. The following examples show how to run in a secure cluster with both yarn-client and yarn-cluster mode. Note that SPARK_CLASSPATH has to be set for both modes, and the example jar is just a placeholder for Spark.
export SPARK_CLASSPATH=/usr/hdp/current/hbase-client/lib/hbase-common.jar:/usr/hdp/current/hbase-client/lib/hbase-client.jar:/usr/hdp/current/hbase-client/lib/hbase-server.jar:/usr/hdp/current/hbase-client/lib/hbase-protocol.jar:/usr/hdp/current/hbase-client/lib/guava-12.0.1.jar
Suppose hrt_qa is a headless acount, user can use following command for kinit:
kinit -k -t /tmp/hrt_qa.headless.keytab hrt_qa
/usr/hdp/current/spark-client/bin/spark-submit –class org.apache.spark.sql.execution.datasources.hbase.examples.HBaseSource –master yarn-client –packages zhzhan:shc:0.0.11-1.6.1-s_2.10 –num-executors 4 –driver-memory 512m –executor-memory 512m –executor-cores 1 /usr/hdp/current/spark-client/lib/spark-examples-1.6.1.2.4.2.0-106-hadoop2.7.1.2.4.2.0-106.jar
/usr/hdp/current/spark-client/bin/spark-submit –class org.apache.spark.sql.execution.datasources.hbase.examples.HBaseSource –master yarn-cluster –files /etc/hbase/conf/hbase-site.xml –packages zhzhan:shc:0.0.11-1.6.1-s_2.10 –num-executors 4 –driver-memory 512m –executor-memory 512m –executor-cores 1 /usr/hdp/current/spark-client/lib/spark-examples-1.6.1.2.4.2.0-106-hadoop2.7.1.2.4.2.0-106.jar
Putting It All Together
We’ve just given a quick overview of how HBase supports Spark at the DataFrame level. With the DataFrame API Spark applications can work with data stored in HBase table as easily as any data stored in other data sources. With this new feature, data in HBase tables can be easily consumed by Spark applications and other interactive tools, e.g. users can run a complex SQL query on top of an HBase table inside Spark, perform a table join against Dataframe, or integrate with Spark Streaming to implement a more complicated system.
What’s Next?
Currently, the connector is hosted in Hortonworks repo, and published as a Spark package. It is in the process of being migrated to Apache HBase trunk. During the migration, we identified some critical bugs in the HBase trunk, and they will be fixed along with the merge. The community work is tracked by the umbrella HBase JIRA HBASE-14789, including HBASE-14795 and HBASE-14796 to optimize the underlying computing architecture for Scan and BulkGet, HBASE-14801 to provide JSON user interface for ease of use, HBASE-15336 for the DataFrame writing path, HBASE-15334 for Avro support, HBASE-15333 to support Java primitive types, such as short, int, long, float, and double, etc., HBASE-15335 to support composite row key, and HBASE-15572 to add optional timestamp semantics. We look forward to producing a future version of the connector which makes the connector even easier to work with.
Acknowledgement
We want to thank Hamel Kothari, Sudarshan Kadambi and Bloomberg team in guiding us in this work and also helping us validate this work. We also want to thank HBase community for providing their feedback and making this better. Finally, this work has leveraged the lessons from earlier Spark HBase integrations and we want to thanks their developers for paving the road.
Reference:
SHC: https://github.com/hortonworks/shc-release
Spark-package: http://spark-packages.org/package/zhzhan/shc
Apache HBase: https://hbase.apache.org/
Apache Spark: http://spark.apache.org/
Editor's Choice


java.lang.NoSuchMethodError: org.json4s.jackson.JsonMethods$.parse(Lorg/json4s/JsonInput;Z)Lorg/json4s/JsonAST$JValue;
at org.apache.spark.sql.execution.datasources.hbase.HBaseTableCatalog$.apply(HBaseTableCatalog.scala:186)
at org.apache.spark.sql.execution.datasources.hbase.HBaseRelation.(HBaseRelation.scala:162)
at org.apache.spark.sql.execution.datasources.hbase.DefaultSource.createRelation(HBaseRelation.scala:49)
at org.apache.spark.sql.execution.datasources.DataSource.resolveRelation(DataSource.scala:318)
at org.apache.spark.sql.DataFrameReader.loadV1Source(DataFrameReader.scala:223)
at org.apache.spark.sql.DataFrameReader.load(DataFrameReader.scala:211)
at org.apache.spark.sql.DataFrameReader.load(DataFrameReader.scala:167)
at withCatalog(:38)
… 55 elided
i am getting above while storing habse in spark 2.3.1
Can someone please update these links and the article?
Hi Bhima,
Did you get any luck here. I am also facing the same issue.
java.lang.NoSuchMethodError: org.json4s.jackson.JsonMethods$.parse(Lorg/json4s/JsonInput;Z)Lorg/json4s/JsonAST$JValue;
at org.apache.spark.sql.execution.datasources.hbase.HBaseTableCatalog$.apply(HBaseTableCatalog.scala:186)
at org.apache.spark.sql.execution.datasources.hbase.HBaseRelation.(HBaseRelation.scala:162)
at org.apache.spark.sql.execution.datasources.hbase.DefaultSource.createRelation(HBaseRelation.scala:49)
at org.apache.spark.sql.execution.datasources.DataSource.resolveRelation(DataSource.scala:318)
at org.apache.spark.sql.DataFrameReader.loadV1Source(DataFrameReader.scala:223)
at org.apache.spark.sql.DataFrameReader.load(DataFrameReader.scala:211)
at org.apache.spark.sql.DataFrameReader.load(DataFrameReader.scala:167)
at withCatalog(:38)
Try to use Scala 2.11 with dependence `shc-core-1.1.0.3.1.2.1-1.jar`:
$ pyspark –master local[*] –jars //shc-core-1.1.0.3.1.2.1-1.jar
I am trying to use SHC to write to Hbase table through Pyspark.
Below is the simple code I used:
import pyspark
from pyspark.sql import SparkSession
spark = SparkSession.builder.appName(“test_hbase”).getOrCreate()
import json
catalog = {
“table”:{“namespace”:”dm_sg_sail”, “name”:”t_sg_sail_credit_card”},
“rowkey”:{“CUSTOMER_IDENTITY_NUMBER”,”CIN_SUFFIX”,”ACCOUNT_NUMBER”,”INSTALMENT_SEQ_NUMBER”},
“columns”:{
“CUSTOMER_IDENTITY_NUMBER”:{“cf”:”rowkey”, “col”:”CUSTOMER_IDENTITY_NUMBER”,”type”:”string”},
“CIN_SUFFIX”:{“cf”:”rowkey”, “col”:”CIN_SUFFIX”,”type”:”string”},
“ACCOUNT_NUMBER”:{“cf”:”rowkey”, “col”:”ACCOUNT_NUMBER”,”type”:”string”},
“INSTALMENT_SEQ_NUMBER”:{“cf”:”rowkey”, “col”:”INSTALMENT_SEQ_NUMBER”,”type”:”string”},
“BILLING_CYCLE”:{“cf”:”creditcard”, “col”:”BILLING_CYCLE”,”type”:”string”},
“PRODUCT_CODE”:{“cf”:”creditcard”, “col”:”PRODUCT_CODE”,”type”:”string”},
“PRODUCT_DESCRIPTION”:{“cf”:”creditcard”, “col”:”PRODUCT_DESCRIPTION”,”type”:”string”},
“BUSINESS_DATE”:{“cf”:”creditcard”, “col”:”BUSINESS_DATE”,”type”:”string”}
}
}
df = spark.read.format(“org.apache.spark.sql.execution.datasources.hbase”).option(catalog=catalog).load()
Error:- Traceback (most recent call last):
File “”, line 1, in
TypeError: option() got an unexpected keyword argument ‘catalog’
Option parameter Catalog is not understood. can anyone help
Try:
df = spark.read.options(catalog=catalog).format(“org.apache.spark.sql.execution.datasources.hbase”).load()
In my case, one of the Column Family will have column qualifiers not predefined. Is it possible to specify schema mapping at Column Family level with complex datatype such as Map?
Hello, how to use this connector with secure authentication using “keytab” ?