

![]()
This is a quest blog from Voltage Security, a Hortonworks partner.
Data Security for Hadoop is a critical requirement for adoption within the enterprise. Organizations must protect sensitive customer, partner and internal information and adhere to an ever-increasing set of compliance requirements. The security challenges these organizations are facing are diverse and the technology is evolving rapidly to keep pace.
An Open Community For Platform Security
The open source community, including Hortonworks, has invested heavily in building enterprise grade security for Apache Hadoop. These efforts include Apache Knox for perimeter security, Kerberos for strong authentication and the recently announce Apache Argus incubator that brings a central administration framework for authorization and auditing.

The major focus when it comes to Hadoop security is ensuring that only the right users are provided with the appropriate access rights, ideally by integrating with existing enterprise identity and access management (IAM) services. More granular, role-based access controls are also valuable, for example SQL-style authorization to Hive and HDFS ACLs already available in Hadoop 2.4 and HDP 2.1.
These security measures provide an important piece of the puzzle to ensure data protection and policy compliance with the complex array of data privacy regulations in force today.
Hortonworks & Voltage: Extending layers of security to the data
Voltage Security augments the work in the community with a data-centric security platform to protect sensitive data across various data stores including Hadoop, securing the data from unauthorized access while at rest, in use and in motion, still maintaining the value of the data for analytics, even in its protected form. Hortonworks and Voltage together are collaborating to provide comprehensive security for the enterprise to enable rapid and successful adoption of Hadoop.
Traditional forms of data de-identification
There are several traditional data de-identification approaches that can be deployed to improve security in the Hadoop environment, such as storage-level encryption and data masking.
- Storage Level Encryption
With storage-level encryption the entire volume that the data set is stored in is encrypted at the disk volume level while “at rest” on the data store, which protects against unauthorized personnel who may have physically obtained the disk, from being able to read anything from it. This is a useful control in a Hadoop cluster or any large data store due to frequent disk repairs and swap-outs. However this does not protect the data from access when the disk is running within the system. Decryption is applied automatically when the data is read by the operating system, and live, vulnerable data is fully exposed to any user or process accessing the system.
- Data Masking
Data masking is a useful technique for obfuscating sensitive data, most often used for creation of test and development data from live production information. However, masked data is intended to be irreversible, which limits its value for many analytic applications and post-processing requirements. Moreover there is no guarantee that the specific masking transformation chosen for a specific sensitive data field fully obfuscates it from identification, particularly when correlated with other data in the Hadoop “data lake”. And, specific masking techniques may or may not be accepted by auditors and assessors, affecting whether they truly meet regulatory compliance requirements and provide safe harbor in the event of a data breach.
A Data-Centric Approach to Security
While these technologies potentially have a place in helping to secure data in Hadoop, none of them solves the problem by themselves. What is needed is an end-to-end, data-centric solution.
A data-centric security approach calls for de-identifying the data as close to its source as possible, replacing the sensitive data elements with usable, yet de-identified, equivalents that retain their format, behavior and meaning. This protected form of the data can then be used in subsequent applications, analytic engines, data transfers and data stores. For Hadoop, the best practice is to never allow sensitive information to reach the HDFS in its live and vulnerable form. De-identified data in Hadoop is protected data, and even in the event of a data breach, yields nothing of value, avoiding the penalties and costs such an event would otherwise have triggered.
Voltage SecureData™ for Hadoop
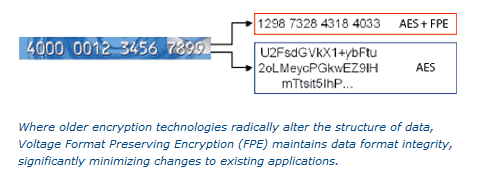
Voltage Security provides such a solution. Voltage Security provides maximum data protection with Voltage SecureData™ for Hadoop, with industry-standard, next generation Voltage Format-Preserving Encryption™ (FPE) and Secure Stateless Tokenization™ (SST) technologies. With Voltage SecureData FPE and SST, two core technology breakthroughs, data protection is applied at the data field and sub-field level, preserves characteristics of the original data, including numbers, symbols, letters and numeric relationships such as date and salary ranges, and maintains referential integrity across distributed data sets so joined data tables continue to operate properly. Voltage FPE, now incorporated in the NIST 800-38G data security standard, and SST, independently validated and peer reviewed, provide high-strength encryption and tokenization of data without altering the original data format, integrity, or analytic value.
 Voltage Secure Data encryption/ tokenization protection can be applied at the source before it gets into Hadoop, or can be evoked during an ETL transfer to a landing zone, or from the Hadoop process transferring the data into HDFS. Once the secure data is in Hadoop, it can be used in its de-identified state for additional processing and analysis without further interaction with the Voltage system. Or the analytic programs running in Hadoop can access the clear text by utilizing the Voltage high-speed decryption/de-tokenization interfaces with the appropriate level of authentication and authorization.
Voltage Secure Data encryption/ tokenization protection can be applied at the source before it gets into Hadoop, or can be evoked during an ETL transfer to a landing zone, or from the Hadoop process transferring the data into HDFS. Once the secure data is in Hadoop, it can be used in its de-identified state for additional processing and analysis without further interaction with the Voltage system. Or the analytic programs running in Hadoop can access the clear text by utilizing the Voltage high-speed decryption/de-tokenization interfaces with the appropriate level of authentication and authorization.
If processed data needs to be exported to downstream analytics in the clear – such as into a data warehouse for traditional BI analysis – there are multiple options for re-identifying the data, either as it exits Hadoop using Hadoop tools or as it enters the downstream systems on those platforms.
A case in point: A supply chain technology company that provides real-time supply chain data and analytics for retailers, manufacturers and trading partners, is using Hortonworks HDP 2.1 Open Source Enterprise Apache Hadoop Platform, with Voltage SecureData for Hadoop to de-identify sensitive data at the field level. The company delivers pharmacy claims reconciliation for top retailers, grocery and pharmacy chain stores, and is responsible for Personally Identifiable Information (PII), Protected Health Information (PHI) subject to HIPAA/ HITECH regulations, and data ingested from thousands of hospitals and health care facilities, such as insurance identification, date information, procedure codes, etc.
Their data science team performs analytics on the de-identified claims data inside the Hadoop environment using MapReduce and Hive, to produce usage trending, market basket insights, and identification of new products and services. Additionally, when specific health risks or need for a procedure or medication are identified through their data analysis, the individual can be quickly and securely re-identified, and that information provided back out to the healthcare provider.
Voltage & Hortonworks
For those building out a Modern Data Architecture based on Hadoop, protection of sensitive data is an area of security where enterprises need a cross platform solution. The combination of Hortonworks and Voltage together provides a comprehensive approach to security across the platform and within the data.
Editor's Choice

