

The upcoming Hive 0.12 is set to bring some great new advancements in the storage layer in the forms of higher compression and better query performance.
Higher Compression
ORCFile was introduced in Hive 0.11 and offered excellent compression, delivered through a number of techniques including run-length encoding, dictionary encoding for strings and bitmap encoding.
This focus on efficiency leads to some impressive compression ratios. This picture shows the sizes of the TPC-DS dataset at Scale 500 in various encodings. This dataset contains randomly generated data including strings, floating point and integer data.

We’ve already seen customers whose clusters are maxed out from a storage perspective moving to ORCFile as a way to free up space while being 100% compatible with existing jobs.
Data stored in ORCFile can be read or written through HCatalog, so any Pig or Map/Reduce process can play along seamlessly. Hive 12 builds on these impressive compression ratios and delivers deep integration at the Hive and execution layers to accelerate queries, both from the point of view of dealing with larger datasets and lower latencies.
Predicate Pushdown
SQL queries will generally have some number of WHERE conditions which can be used to easily eliminate rows from consideration. In older versions of Hive, rows are read out of the storage layer before being later eliminated by SQL processing. There’s a lot of wasteful overhead and Hive 12 optimizes this by allowing predicates to be pushed down and evaluated in the storage layer itself. It’s controlled by the setting hive.optimize.ppd=true.
This requires a reader that is smart enough to understand the predicates. Fortunately ORC has had the corresponding improvements to allow predicates to be pushed into it, and takes advantages of its inline indexes to deliver performance benefits.
For example if you have a SQL query like:
SELECT COUNT(*) FROM CUSTOMER WHERE CUSTOMER.state = ‘CA’;
The ORCFile reader will now only return rows that actually match the WHERE predicates and skip customers residing in any other state. The more columns you read from the table, the more data marshaling you avoid and the greater the speedup.
A Word on ORCFile Inline Indexes
Before we move to the next section we need to spend a moment talking about how ORCFile breaks rows into row groups and applies columnar compression and indexing within these row groups.
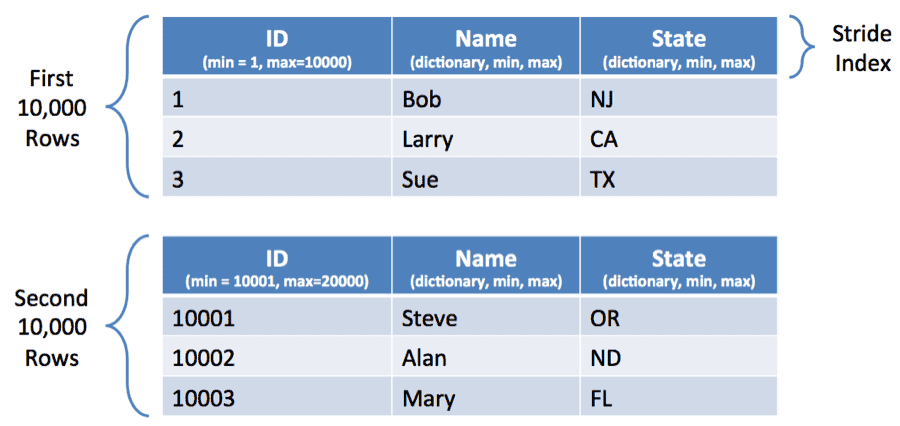
Turning Predicate Pushdown to 11
ORC’s Predicate Pushdown will consult the Inline Indexes to try to identify when entire blocks can be skipped all at once. Some times your dataset will naturally facilitate this. For instance if your data comes as a time series with a monotonically increasing timestamp, when you put a where condition on this timestamp, ORC will be able to skip a lot of row groups.
In other instances you may need to give things a kick by sorting data. If a column is sorted, relevant records will get confined to one area on disk and the other pieces will be skipped very quickly.
Skipping works for number types and for string types. In both instances it’s done by recording a min and max value inside the inline index and determining if the lookup value falls outside that range.
Sorting can lead to very nice speedups. There is a trade-off in that you need to decide what columns to sort on in advance. The decision making process is somewhat similar to deciding what columns to index in traditional SQL systems. The best payback is when you have a column that is frequently used and accessed with very specific conditions and is used in a lot of queries. Remember that you can force Hive to sort on a column by using the SORT BY keyword when creating the table and setting hive.enforce.sorting to true before inserting into the table.
ORCFile is an important piece of our Stinger Initiative to improve Hive performance 100x. To show the impact we ran a modified TPC-DS Query 27 query with a modified data schema. Query 27 does a star schema join on a large fact table, accessing 4 separate dimension tables. In the modified schema, the state in which the sale is made is denormalized into the fact table and the resulting table is sorted by state. In this way, when the query scans the fact table, it can skip entire blocks of rows because the query filters based on the state. This results in some incremental speedup as you can see from the chart below.
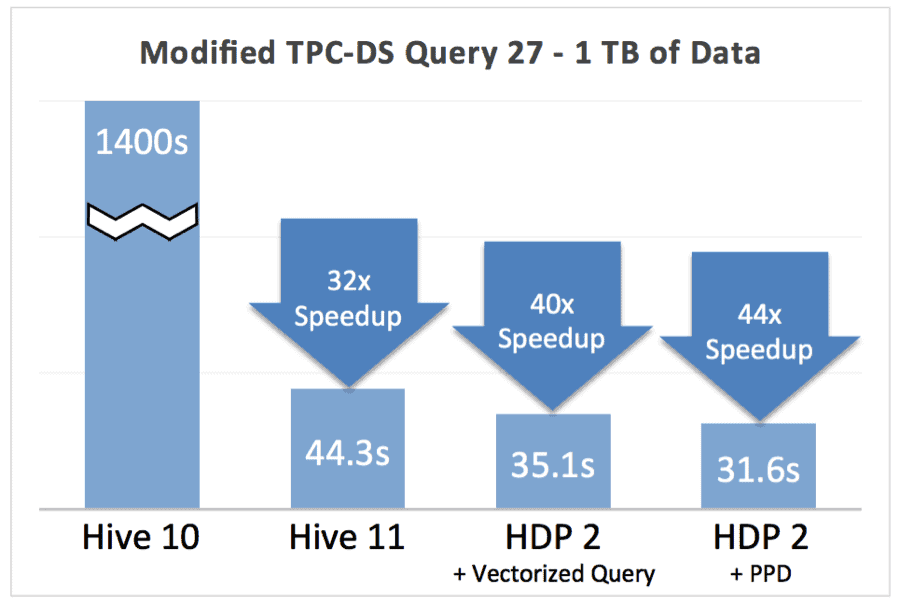
This feature gives you the best bang for the buck when:
- You frequently filter a large fact table in a precise way on a column with moderate to large cardinality.
- You select a large number of columns, or wide columns. The more data marshaling you save, the greater your speedup will be.
Using ORCFile
Using ORCFile or converting existing data to ORCFile is simple. To use it just add STORED AS orc to the end of your create table statements like this:
CREATE TABLE mytable (
...
) STORED AS orc;
To convert existing data to ORCFile create a table with the same schema as the source table plus stored as orc, then you can use issue a query like:
INSERT INTO TABLE orctable SELECT * FROM oldtable;
Hive will handle all the details of conversion to ORCFile and you are free to delete the old table to free up loads of space.
When you create an ORC table there are a number of table properties you can use to further tune the way ORC works.
| Key | Default | Notes |
orc.compress |
ZLIB |
Compression to use in addition to columnar compression (one of NONE, ZLIB, SNAPPY) |
orc.compress.size |
262,144 (= 256 KiB) |
Number of bytes in each compression chunk |
| orc.stripe.size | 268,435,456 (= 256 MiB) |
Number of bytes in each stripe |
orc.row.index.stride |
10,000 |
Number of rows between index entries (must be >= 1,000) |
orc.create.index |
true |
Whether to create inline indexes |
For example let’s say you wanted to use snappy compression instead of zlib compression. Here’s how:
CREATE TABLE mytable (
...
) STORED AS orc tblproperties ("orc.compress"="SNAPPY");
Try It Out
All these features are available in our HDP 2 Beta and we encourage you to download, try them out and give us your feedback.
Editor's Choice

