![Distributed Pricing Engine using Dockerized Spark on YARN w/ HDP 3.0 [Part 4/4]](/wp-content/themes/cloudera/assets/images/default-banner/GettyImages-1287640296-1382x400.jpg)

This blog post was published on Hortonworks.com before the merger with Cloudera. Some links, resources, or references may no longer be accurate.
This is the finale of the blog series (see part 1, part 2, part 3) where having discussed the problem domain, looked at the functional and architectural aspects and prepared the environment, we are now ready to execute a few pricing calculations.
SSH into the cluster gateway node and download the following from repo:
- compute/compute-engine-spark-1.0.0.jar
- compute/scripts/compute-price.sh
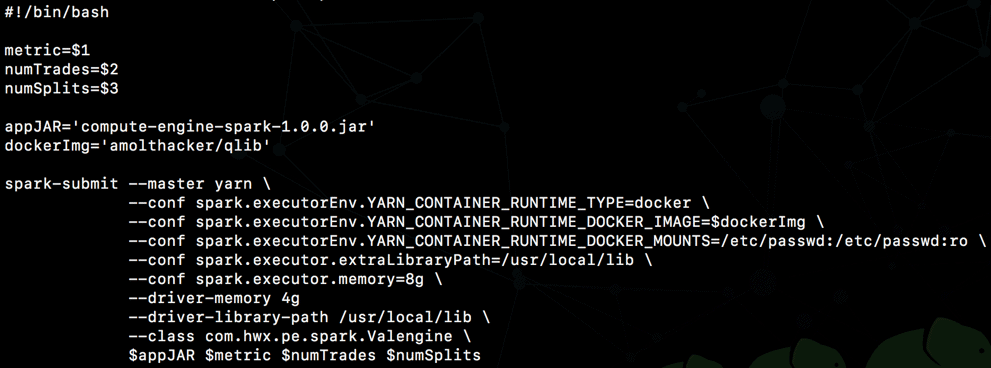
Notice the directives around using Docker as executor env for Spark on YARN in client mode.
You should now be ready to simulate a distributed pricing compute using the following command:
./compute-price.sh <metric> <numTrades> <numSplits>
where metric:
- FwdRate: Spot Price of Forward Rate Agreement (FRA)
- NPV: Net Present Value of a vanilla fixed-float Interest Rate Swap (IRS)
- OptionPV: Net Present Value of a European Equity Put Option average over multiple algorithmic calcs (Black-Scholes, Binomial, Monte Carlo)
eg: ./compute-price.sh OptionPV 5000 20
And see the job execute as follows:
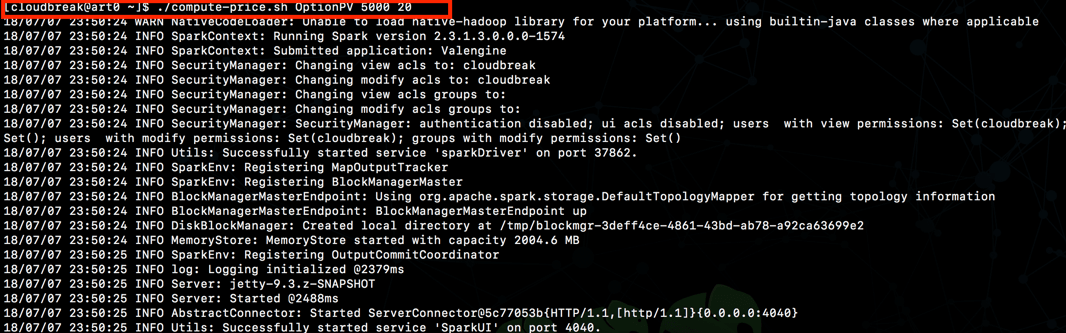
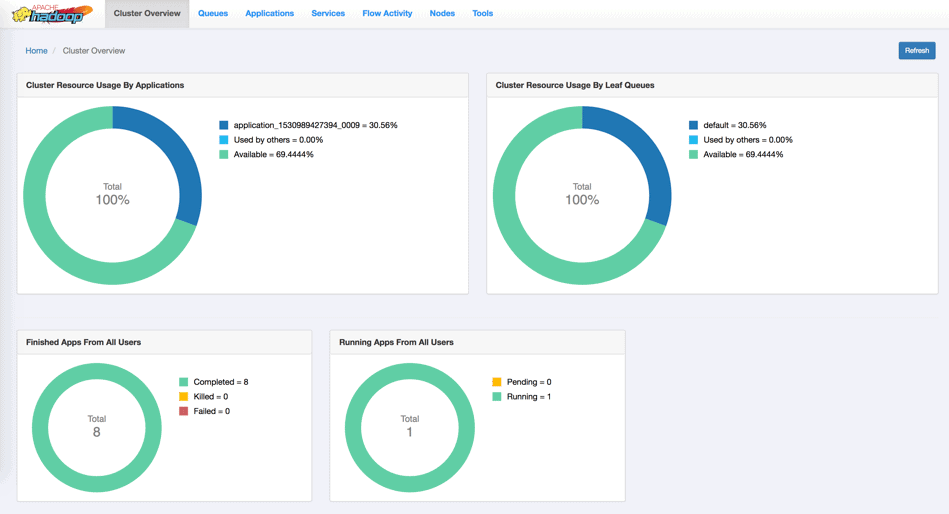

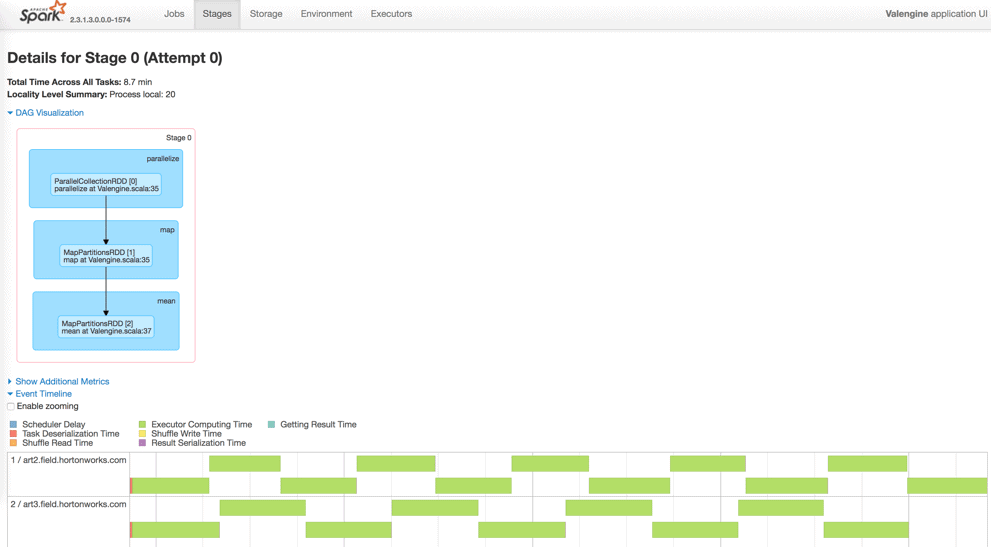
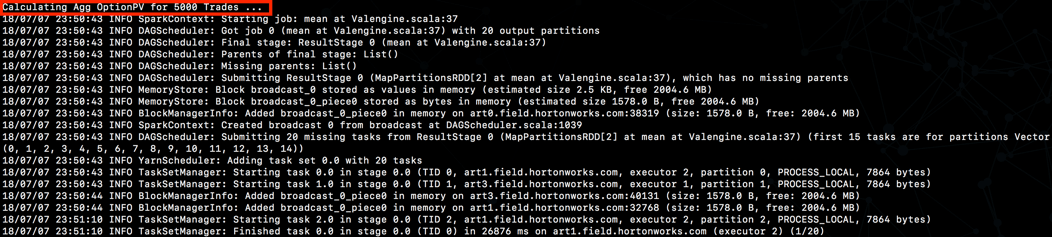
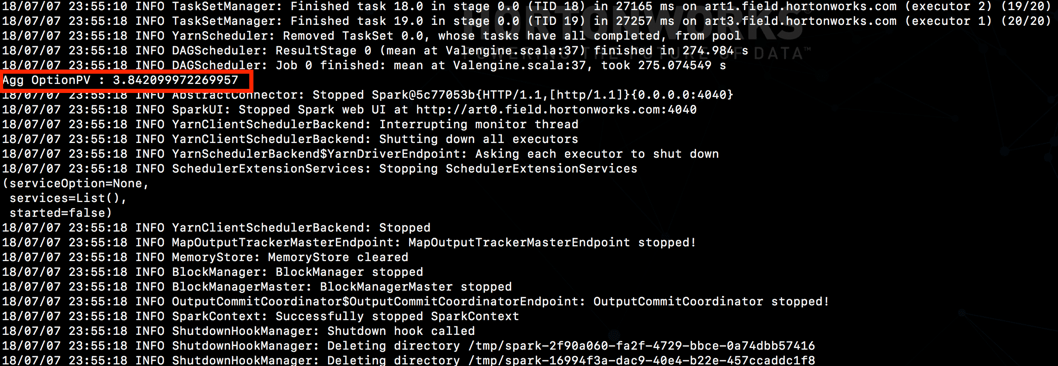
Wrapping up …
HDP 3.0 is pretty awesome right!!! It is now GA and I can tell you, if a decade ago you thought Hadoop was exciting, this will blow your mind away!!
In this blog series, we’ve just scratched the surface and looked at only one of the myriad compute centric aspects of innovation in the platform. For a more detailed read on platform capabilities, direction and unbound possibilities I urge you to read the blog series from folks behind this.

Editor's Choice

